Extracting Text from PDF Documents By Search
- Introduction
- This tutorial shows how to extract text from PDF documents by text search using
the AutoDocSearch™ plug-in for
Adobe® Acrobat®.
The AutoDocSearch software provides functionality for searching PDF files and extracting matching text into a spreadsheet
or a text file.
It can be used to search for and extract the following types of text:
- Custom text strings such as as “John Smith” or “Monthly Statement”
- Text patterns such as social security (SSN), phone and account numbers, emails, and dates etc.
- Text that matches a keyword from a user-defined list, for example day of the week (Monday, Tuesday,..) or a month (January, February,…).
The search results can be formatted by adding a custom text and extracting only specific parts of the search output. The output can be formatted into many popular formats such as CSV, XML, and HTML etc. - Prerequisites
- You need a copy of Adobe® Acrobat® along with the AutoDocSearch™ plug-in installed on your computer in order to use this tutorial. You can download trial versions of both the Adobe® Acrobat® and the AutoDocSearch™ plug-in.
- Contents
- The tutorial contains the following examples:
Extracting a Single Text Pattern
- Overview ↑overview
- The first example illustrates how to extract invoice numbers from a set of individual PDF documents (each file represents an invoice). The same method can be used to extract invoice numbers from a single PDF document that contains multiple invoices. The extracted text is saved into a spreadsheet-ready CSV file or a plain text file. Here is a screenshot of the sample PDF document with an invoice number highlighted:
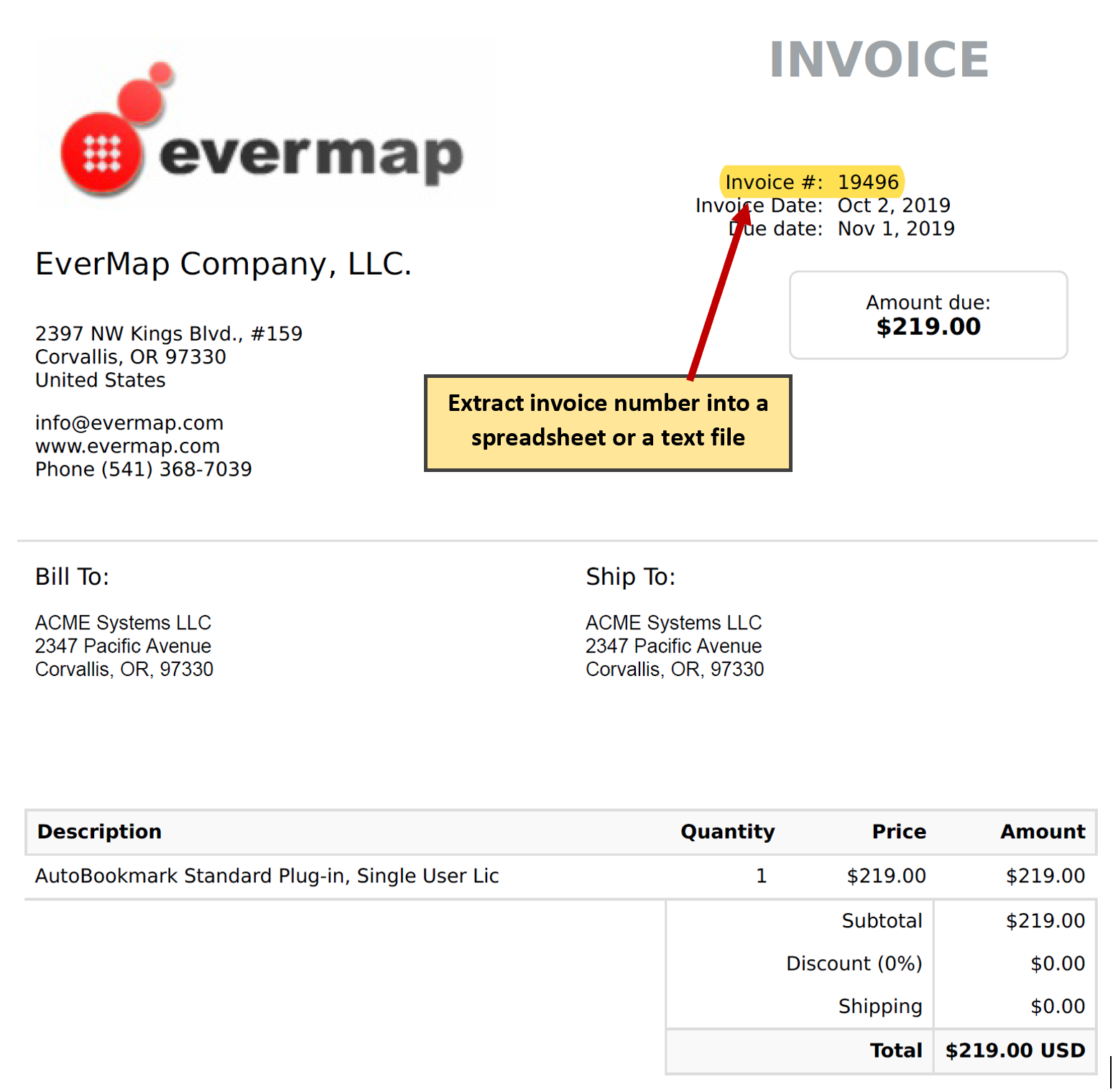
- Specify a Search Pattern ↑overview
- Select "Plug-ins > AutoDocSearch Plug-in > Search PDF Files..." from the main Adobe Acrobat menu to open the "Search PDF Files" dialog. Next, type the following search expression into the text box:
-
Invoice #: \d+
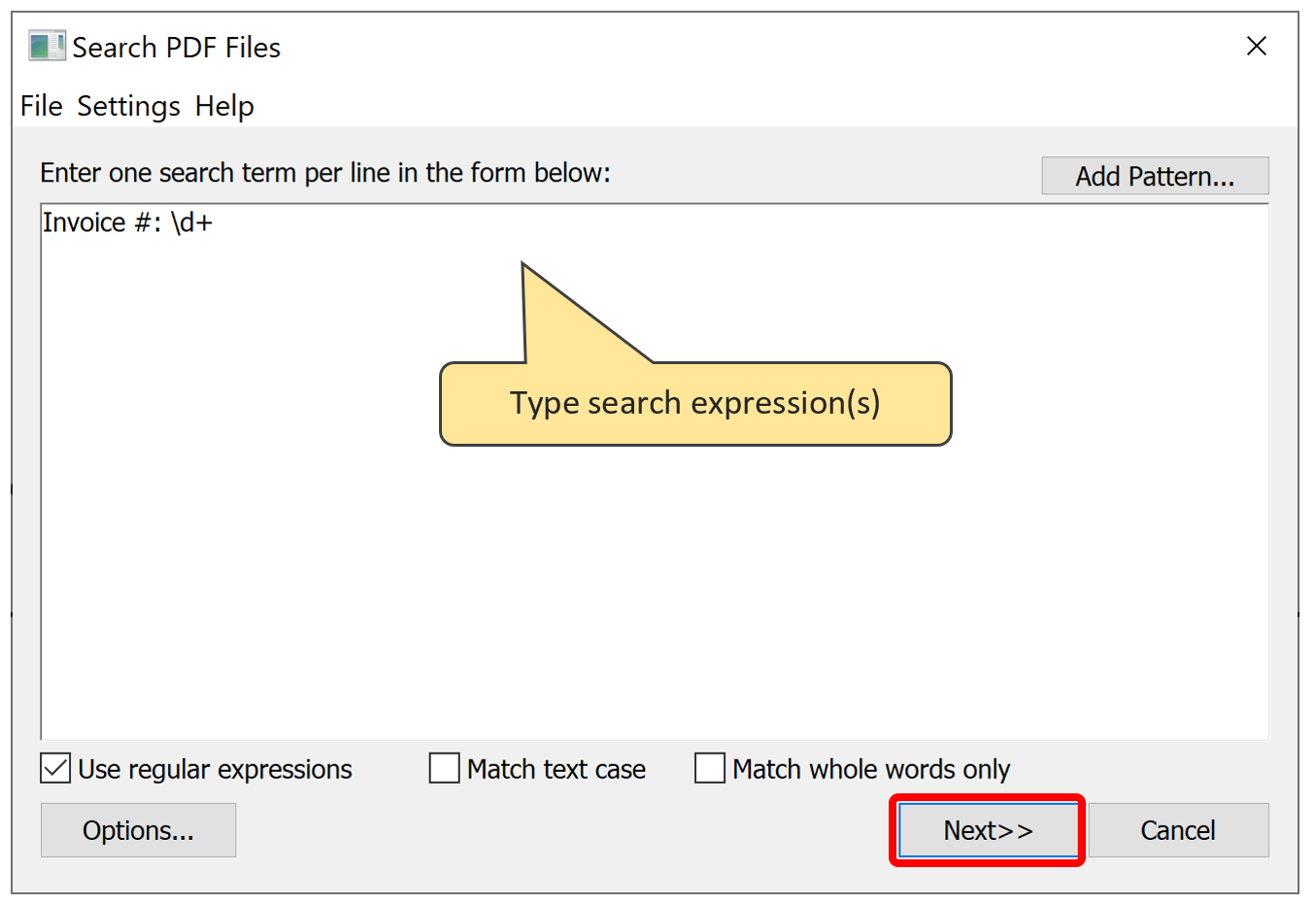
- The AutoDocSearch uses regular expression (regex for short) syntax to perform a text search. Regular expressions are a powerful tool for finding and extracting complex patterns from text documents. This is common language for performing text search in many applications and programming languages with a large amount of examples available online.
- Let's see what this search expression actually means. The Invoice #: part is searching for the text "as-is", while the \d+ part of the expression is a special regex character class \d that matches any digit [0-9]. The + is a quantifier that means "match a previous character one or more times". The \d+ will match any number of digits, for example: 326436 or 000001223. The Invoice #: \d+ expession finds all occurences of the "Invoice #: " text that is followed by one or more digit. For example: Invoice #: 19361 or Invoice #: 001.
- Press "Next>>" button to advance to the next step.
- Select PDF Files to Search ↑overview
- Press "Add Files" button on the "Select Input Files" dialog to select files to search.
- Use "Open" dialog to select one or more PDF files. You can select multiple files by holding Shift key and clicking on the first and last files in the list.
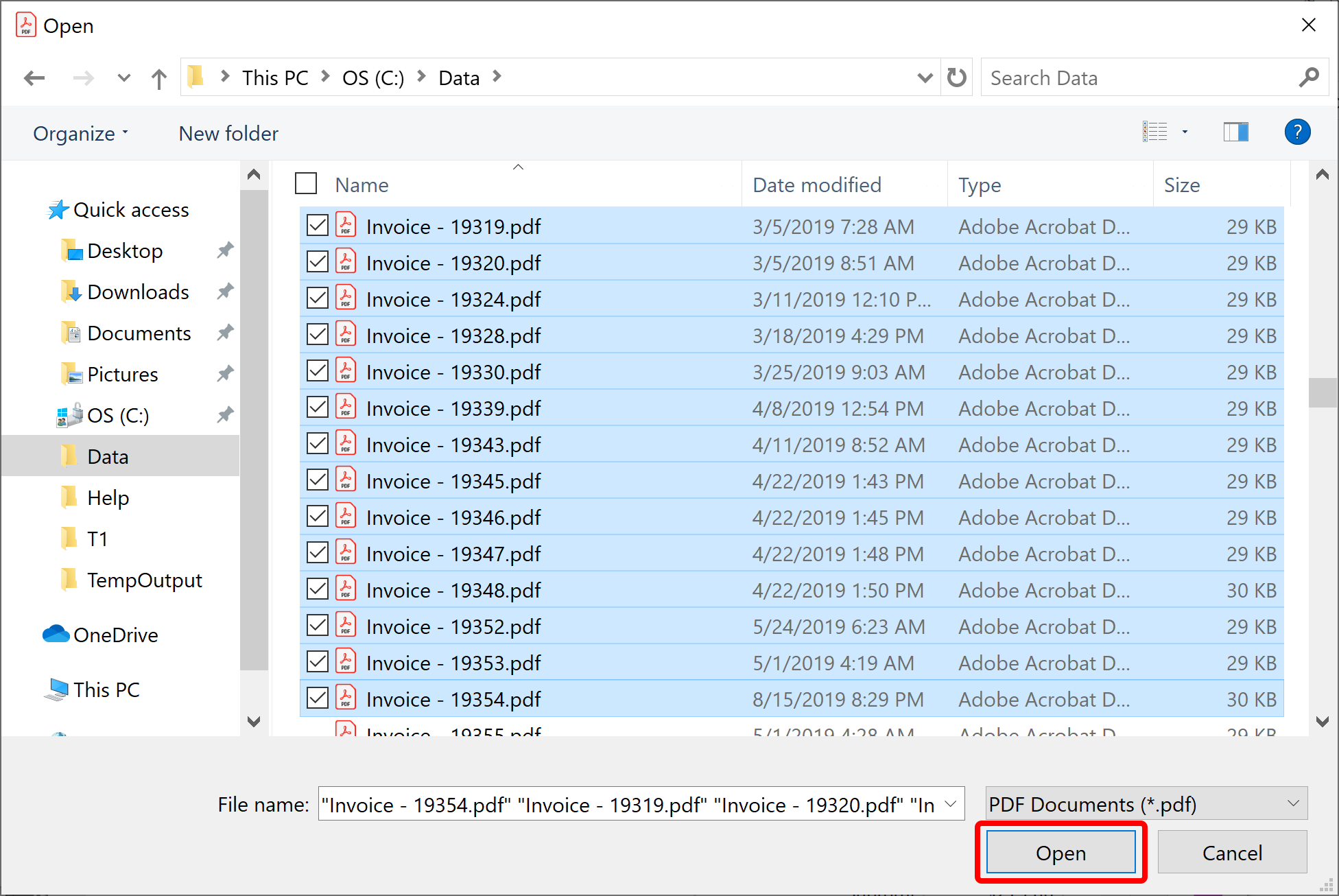
- Press "Open" button to accept selected files.
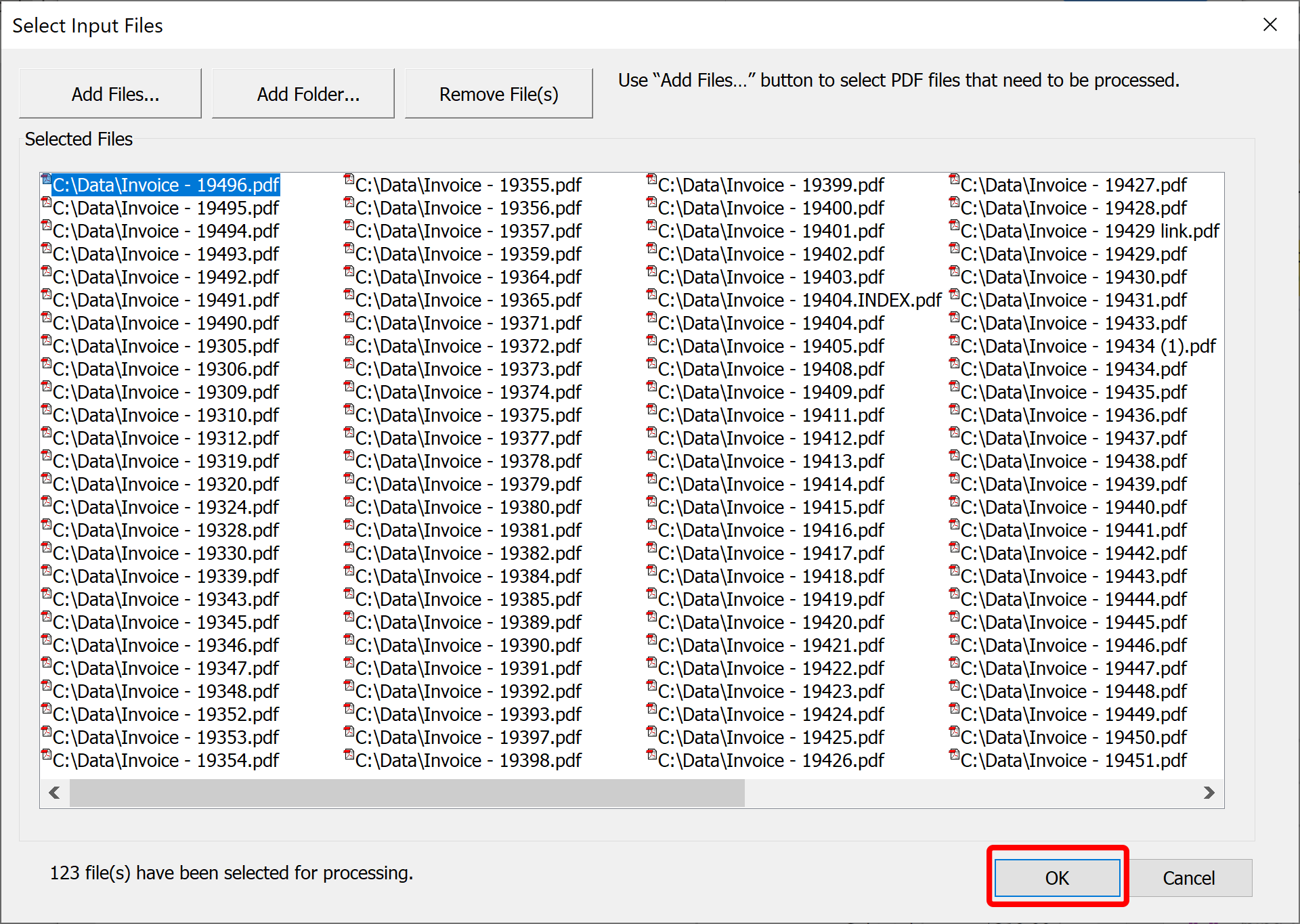
- Now press OK button to start searching the files.
- Examine the Search Results ↑overview
- The matching text is displayed in the "Search Results" dialog. Resize the window for a better view and/or adjust the width of the Text Match column. Optionally, click on the results in the list to display a corresponding page location.
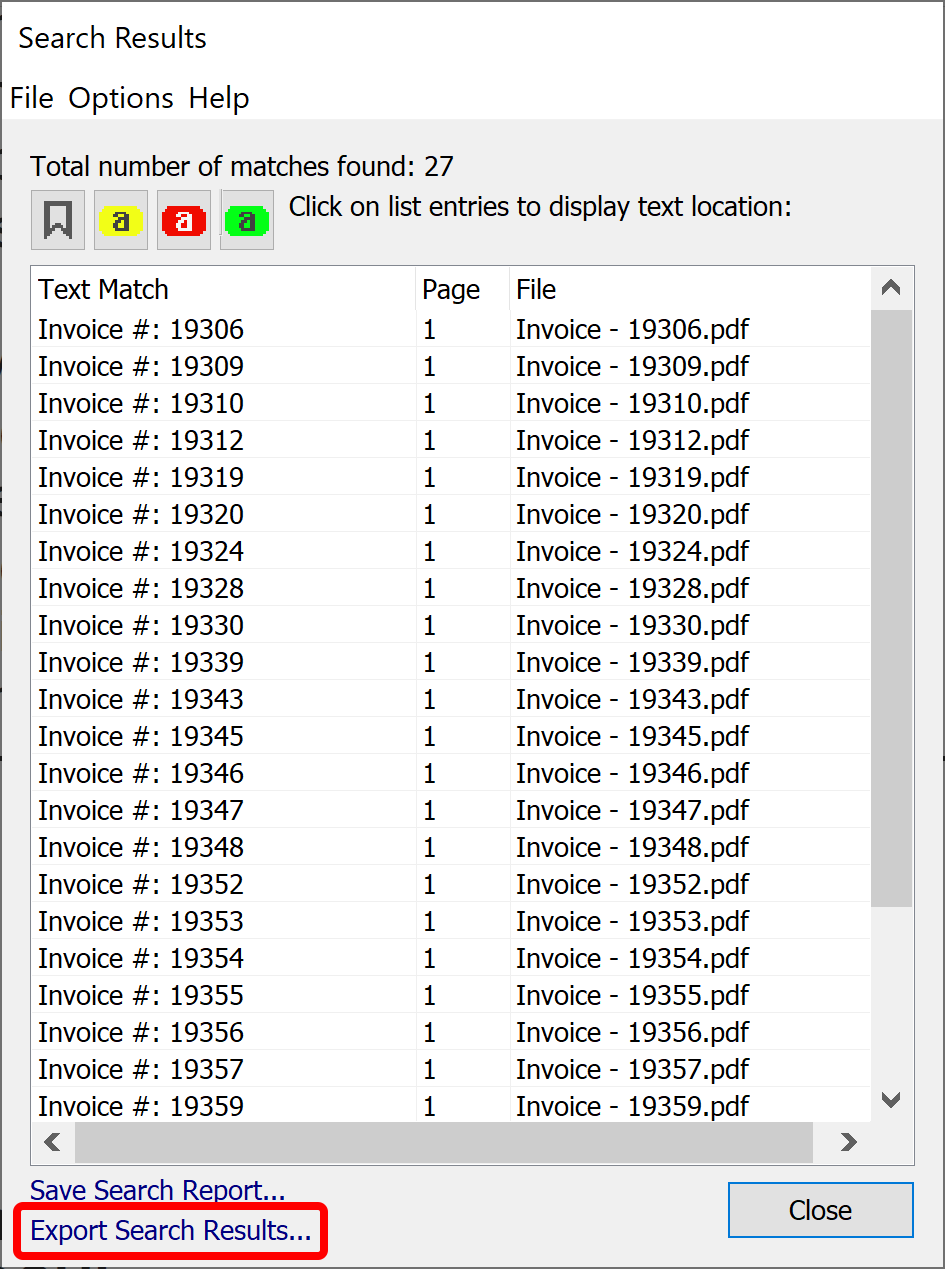
- Save Resuts as a Spreadsheet ↑overview
- You can save search results into either a spreadsheet-ready CSV file or into a plain text file. Click "Extract Search Result" link at the bottom of the screen and select a desired output format. Let's examine the spreadsheet format first.
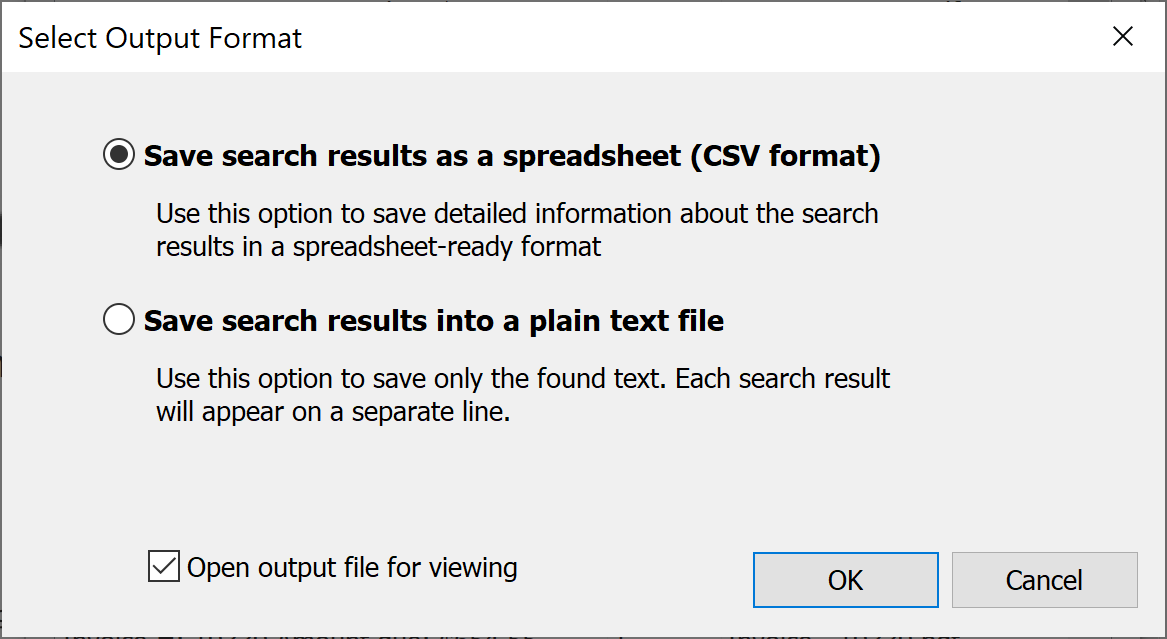
- Select a spreadsheet option and press OK to select the output file location and name.
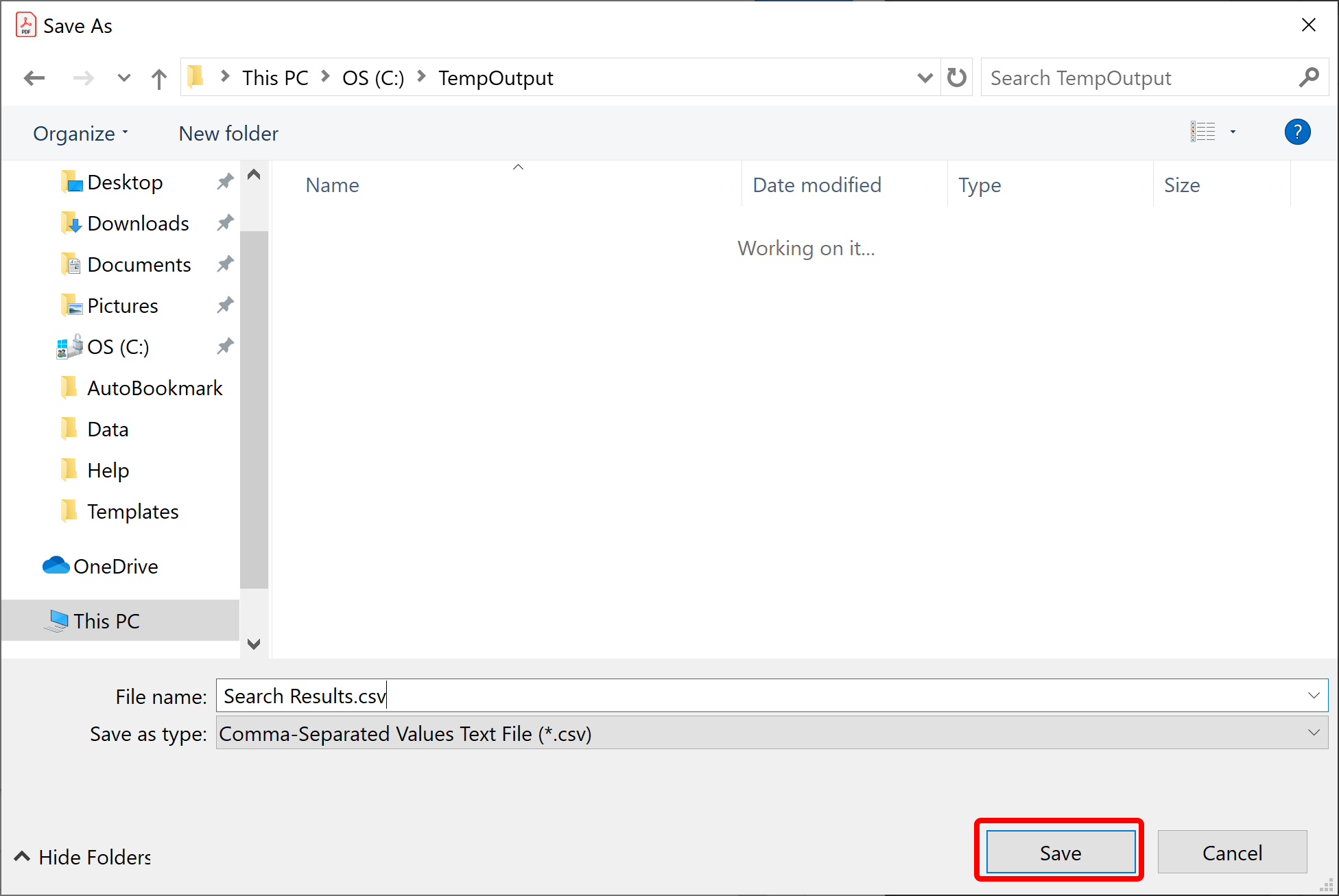
- The output CSV file will be automatically open in Excel (or any other application that is designated to handle CSV files on your computer).
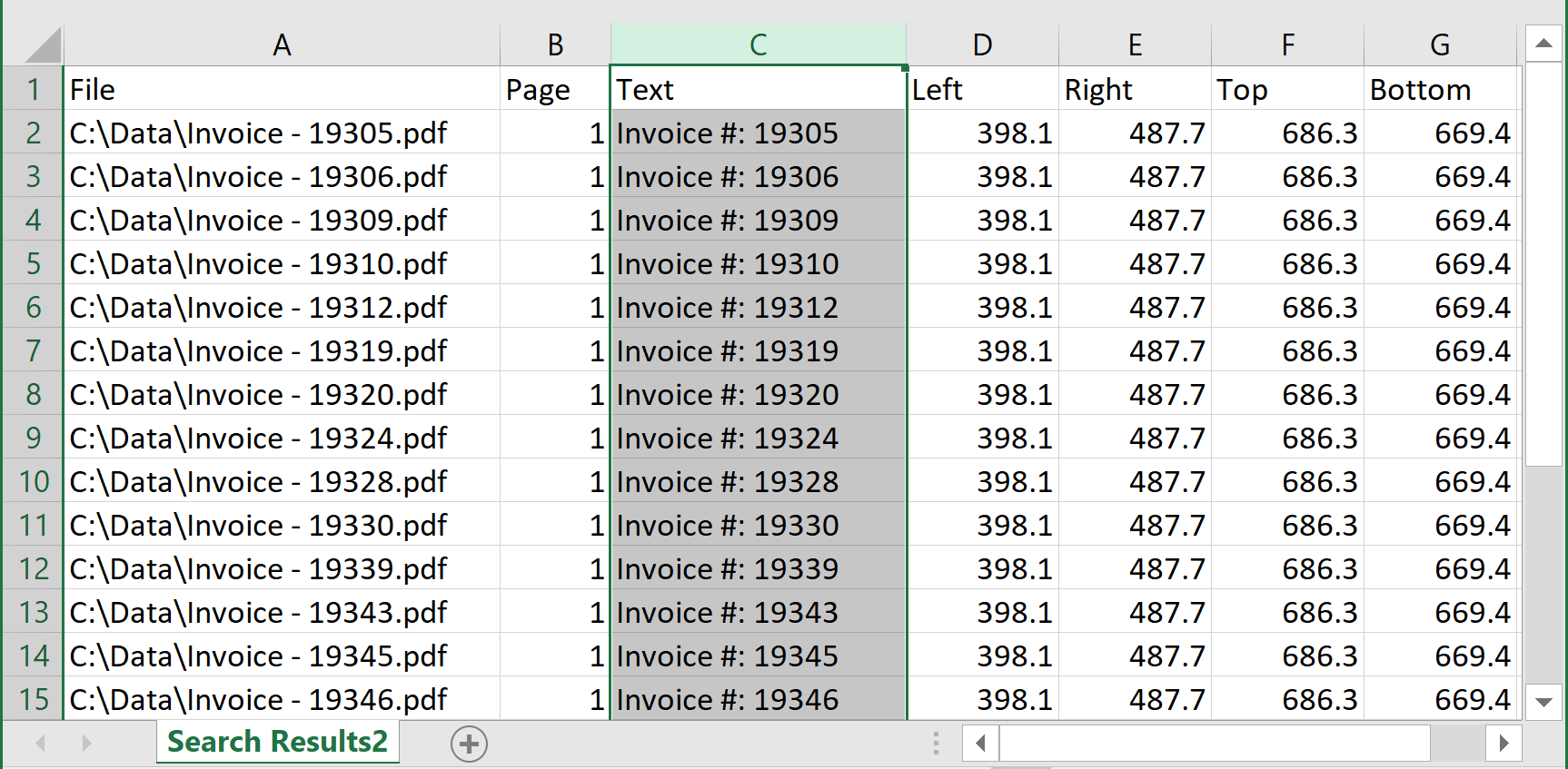
- Each text match is stored as a separate record. The spreadsheet contains the following columns:
- Full path to the PDF file that contains the text match
- Page number where the text is located
- Matching text
- Page coordinates that describe the location of the text on the page (Left, Right, Top, Bottom). Coordinates are provided in the PDF coordinate system with origin in the lower-left corner of the page, measurement units are points (72 points = 1 inch).
- Search rule number (1, 2, 3..). This is helpful in case if multiple search rules/expressions have been used.
- Save Search Results into a Text File ↑overview
- Alternatively, the matching text can be saved into a plain text file. Click "Extract Search Result..." link at the bottom of the "Search Results" dialog and select a text output option and press OK button:
- Select output file location an name:
- The output text file will be automatically open in Notepad (or any other application that is designated to handle text files on your computer).
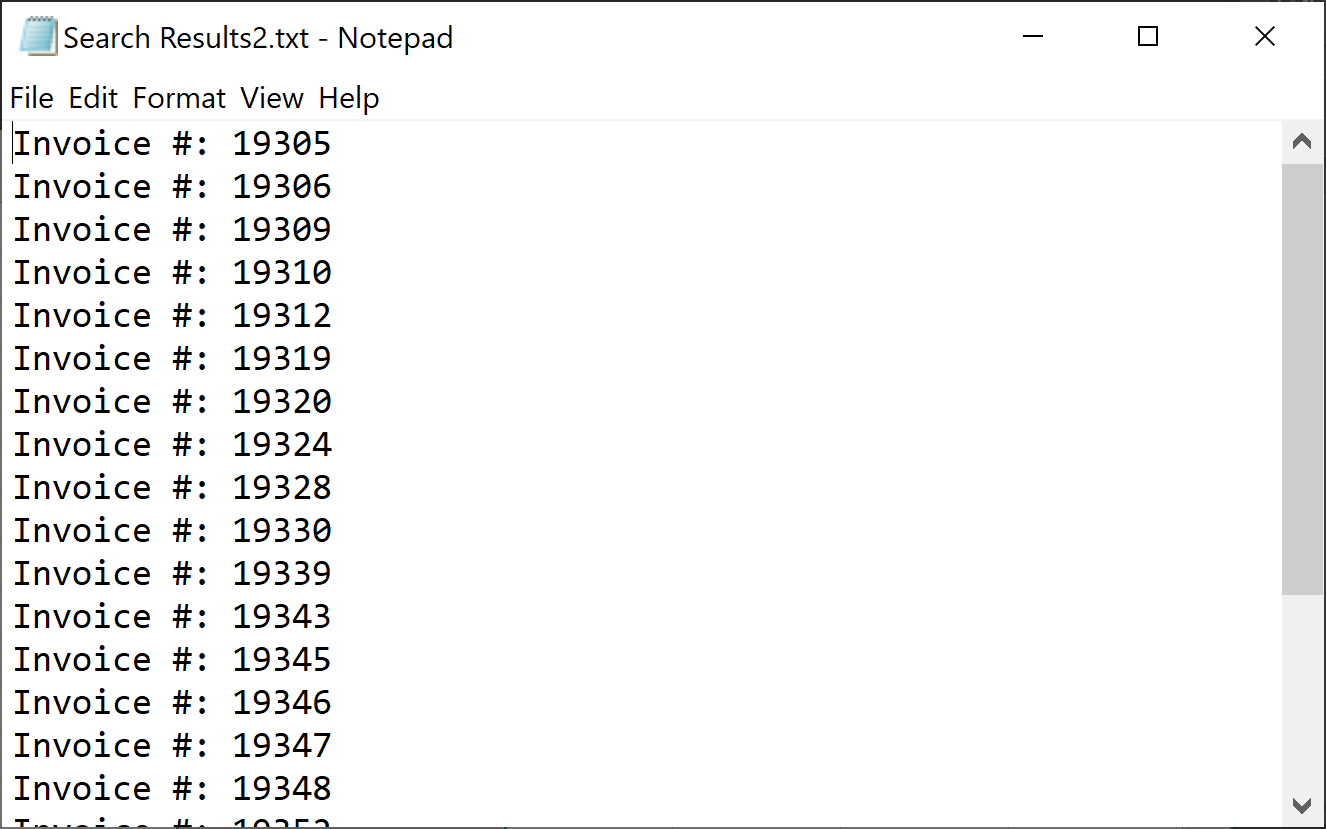
- Each text match appears on a separate line. Unlike the spreadsheet option, the text export saves only matching text and does not provide any additonal information about the search results.
Extracting Multiple Text Patterns with Formatting
- Overview
- The second example illustrates how to extract multiple text patterns from a single PDF page. We are going to extract an invoice number and "amount due" from a set of individual PDF documents (each file represents an invoice). The extracted text is saved into a spreadsheet-ready CSV file or a plain text file. Here is a screenshot of the sample PDF document with an invoice number and "amount due" fields highlighted:
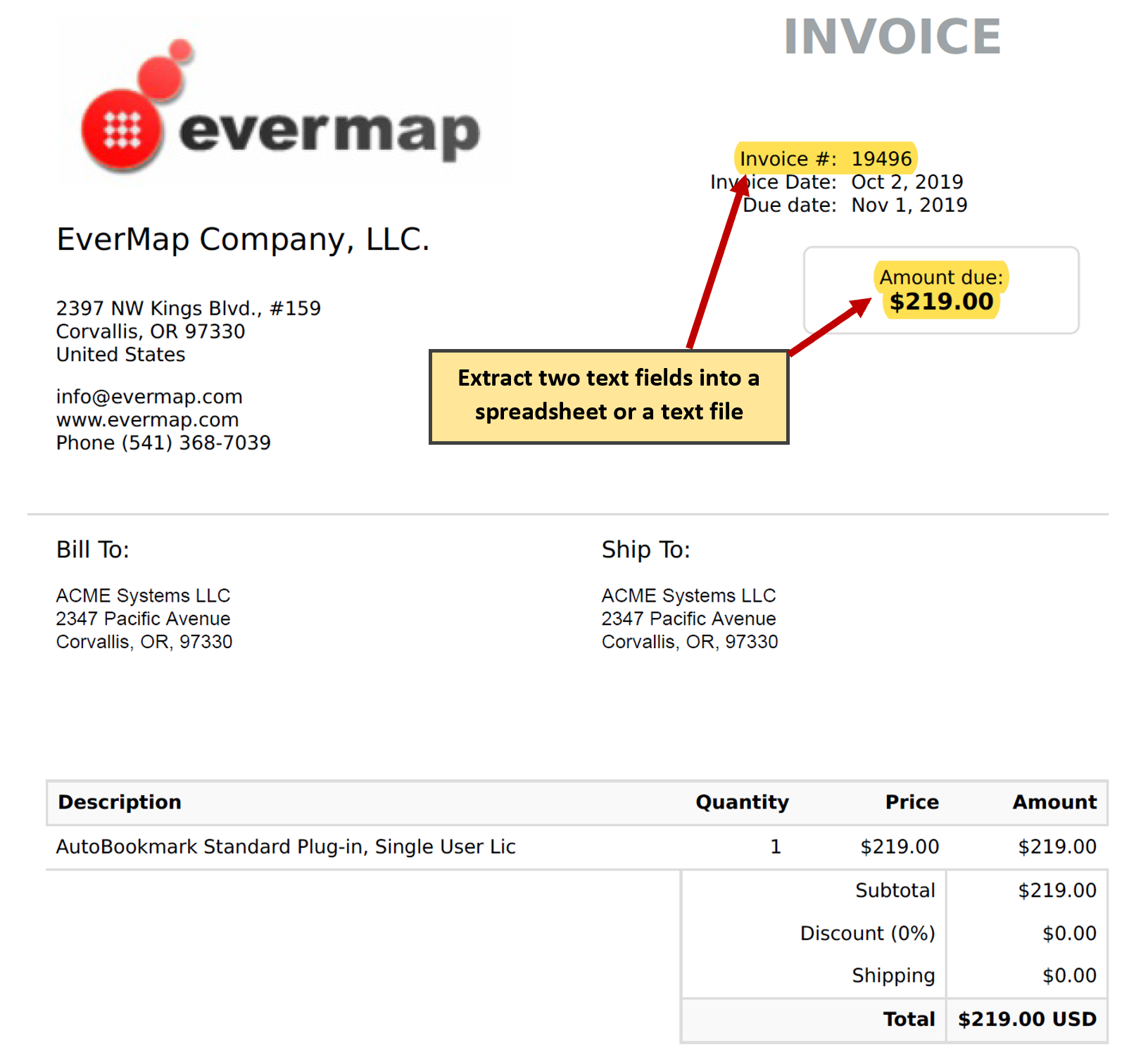
- The process is essentially the same as for the single text pattern extraction. The difference is in the more advanced search expression.
- Specify Search Pattern ↑overview
- Select "Plug-ins > AutoDocSearch Plug-in > Search PDF Files..." from the main Adobe Acrobat menu to open "Search PDF Files" dialog. Next, type the following search expression into the text box:
-
(Invoice #: \d+)[\s\S]+(Amount due: [$]\d+[,]?\d+[.]\d{2})(?#format=\1 \2)
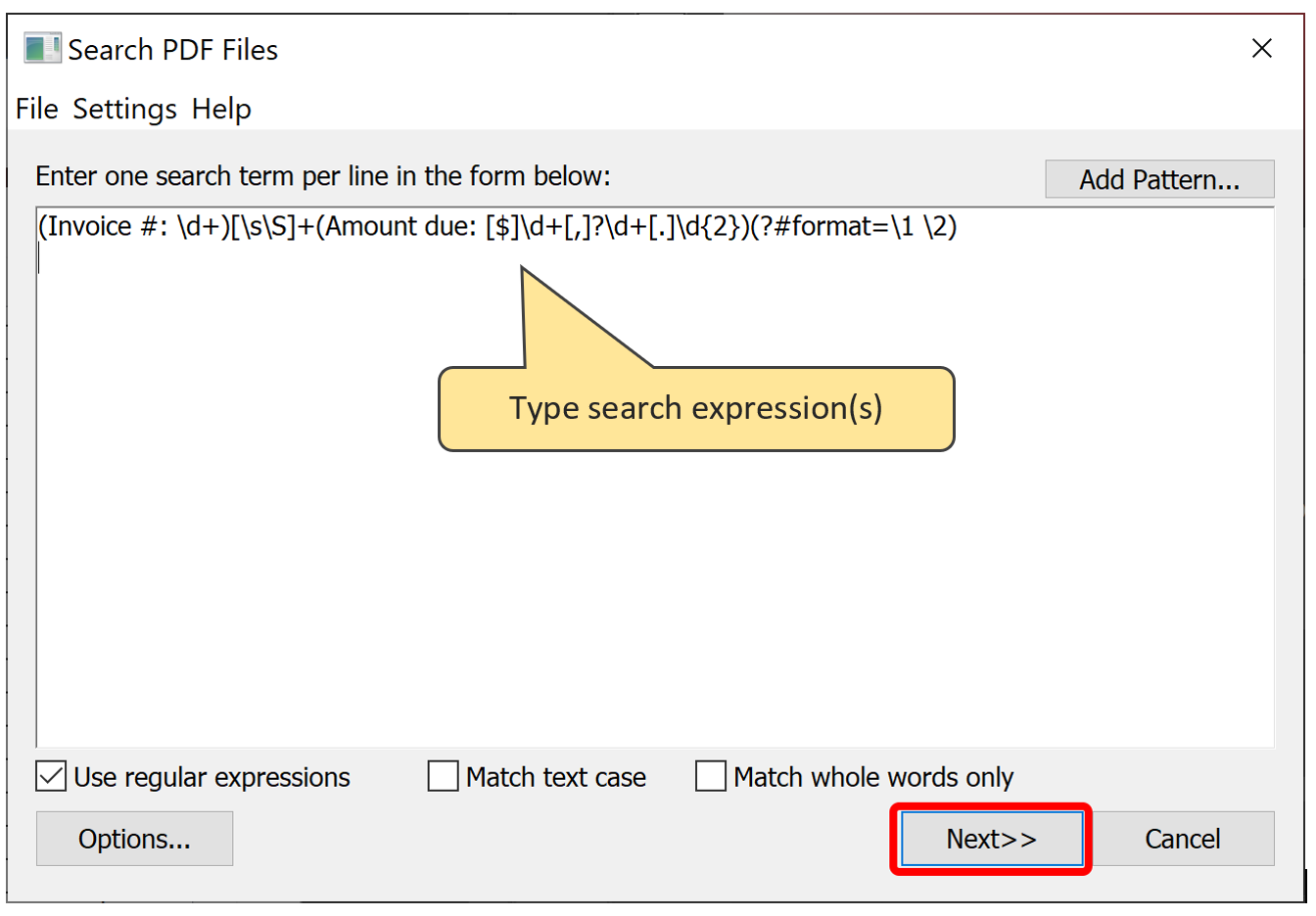
- This regular expression looks complicated at first. Let's examine it in detail. This expression consists of 4 logical parts:
-
- First capturing group that extracts an invoice number (for example: Invoice #: 37603)
- Text that appears between an invoice number and "amount due" field. It is matching one or more "space" and "non-space" characters.
- Second capturing group that extracts an "amount due" field (for example: Amount due $1,203.55).
- Special formatting expression that outputs only capturing groups 1 and 2 and ignores the rest of the text.

- Parentheses are used in regular expression to group a part of the expression together into a capturing group. It is used to refer to the specific part of the matching text after the match has happend. By using capturing groups we are able to refer to an invoice number and "amount due" field in the format expression such as \1 and \2 correspondingly. This allows to extract only these two text fields and ignore all other text that may appear between them.
- IMPORTANT: Note that PDF documents are not "linear" text files. The text location on the page is totally unrelated to its actual positon in the text content. The order of the text can be different from an assumed reading order. Most often, the text does follow a natural top-to-bottom reading order, but it is totally up to the application that generated a specific PDF file. It is always a good idea to inspect the actual text order prior to writing any search expressions. You can do that by selecting text on the page and copy/pasting it into another text editor. Knowing the actual text order is cricual for writing a correct search expression.
- Formatting the Search Results
- The regular expression in this example is using an optional (?#format=....) expression. If this expression is omitted, then the search result will contain all text that is matched by the search pattern. In our case, this will include all text that appears between an invoice number and "amount due". The format expression can be used not only to refer to the specific parts of the search results, but also for changing the text order (for example, placing "amount due" field before the invoice number) and inserting a custom text into the output.
- Let's see what we can do to the search results with different formatting expressions:
-
Format Expression Sample Output (?#format=\1 \2) Invoice #: 37452 Amount due: $1,503.00 (?#format=\2 \1) Amount due: $1,503.00 Invoice #: 37452 (?#format=Accounts Payable: \1 (\2)) Accounts Payable: Invoice #: 37452 (Amount due: $1,503.00) - What if we need to extract only the invoice numbers and amounts, but without the labels (Invoice #: and Amount due:)? This can be easily accomplished by changing the capturing groups and placing them around the parts that matches the numbers and leaving the labels out. Here are some examples:
-
Regular Expression Sample Output Invoice #: (\d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format=\1 \2) 37452 $1,503.00 Invoice #: (\d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format=Pay \2 for invoice \1) Pay $1,503.00 for invoice 37452 (Invoice #: \d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format=\1 (\2)) Invoice #: 37452 ($1,503.00) - See Advanced: Exporting Results as XML Data File section below for more examples of data formatting and structural output.
- Select PDF Files to Search ↑overview
- Press "Next>>" button (on "Search PDF Files" dialog) to advance to the next step. The rest of the step are identical to the first example. We are going to repeat them here for convinience.
- Press "Add Files" button on the "Select Input Files" dialog to select files to search.
- Use "Open" dialog to select one or more PDF files. You can select multiple files by holding Shift key and clicking on the first and last files in the list.
- Press "Open" button to accept selected files.
- Now press OK button to start searching the files.
- Examine the Search Results ↑overview
- The matching text is displayed in the "Search Results" dialog. Resize the window for a better view and/or adjust the width of the Text Match column. Optionally, click on the results in the list to display a corresponding page location.
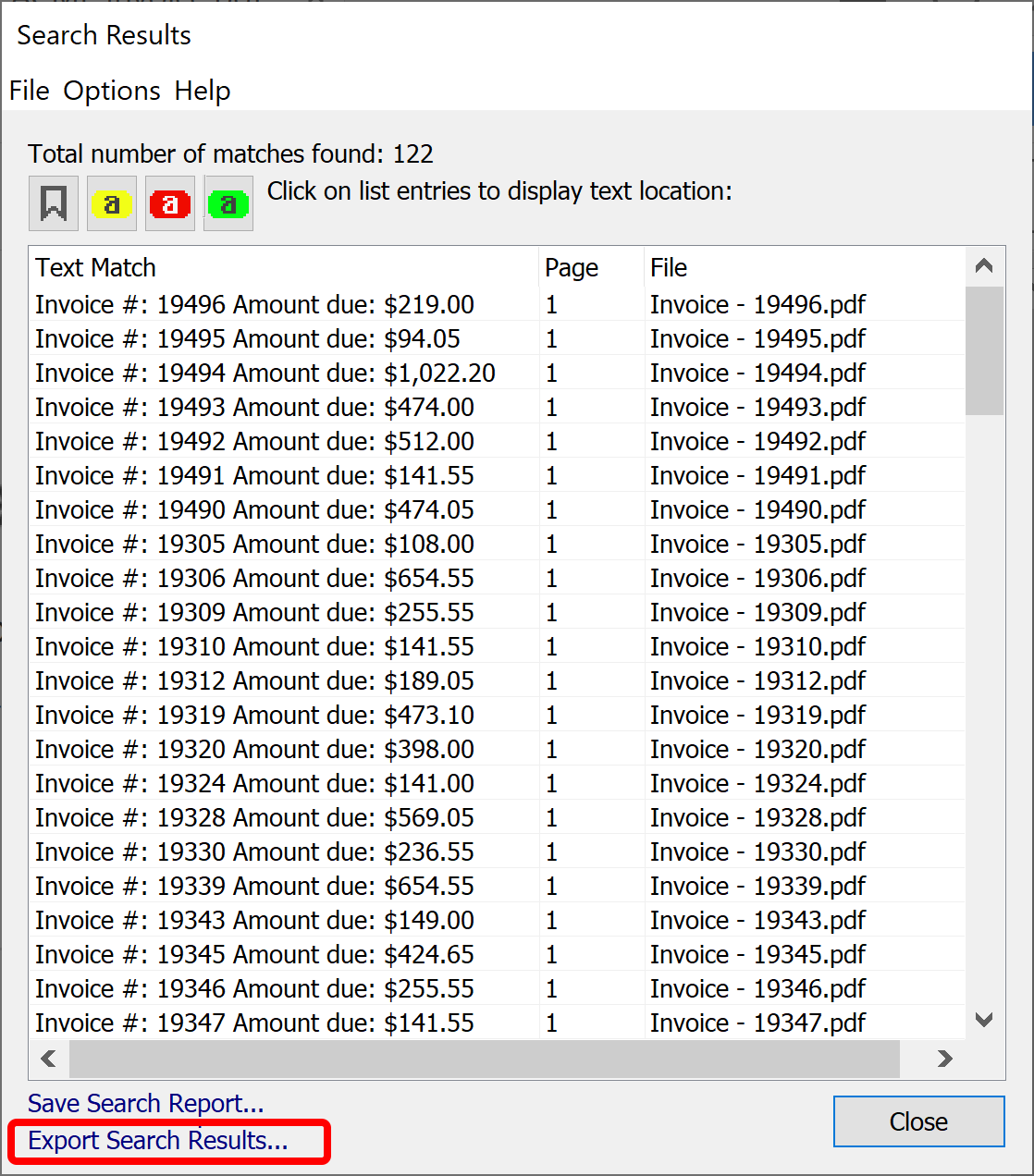
- Save Resuts as a Spreadsheet ↑overview
- You can save search results into either a spreadsheet-ready CSV file or into a plain text file. Click "Extract Search Result" link at the bottom of the screen and select a desired output format. Let's examine the spreadsheet format first.
- Select a spreadsheet option and press OK to select the output file location and name.
- The output CSV file will be automatically open in Excel (or any other application that is designated to handle CSV files on your computer).
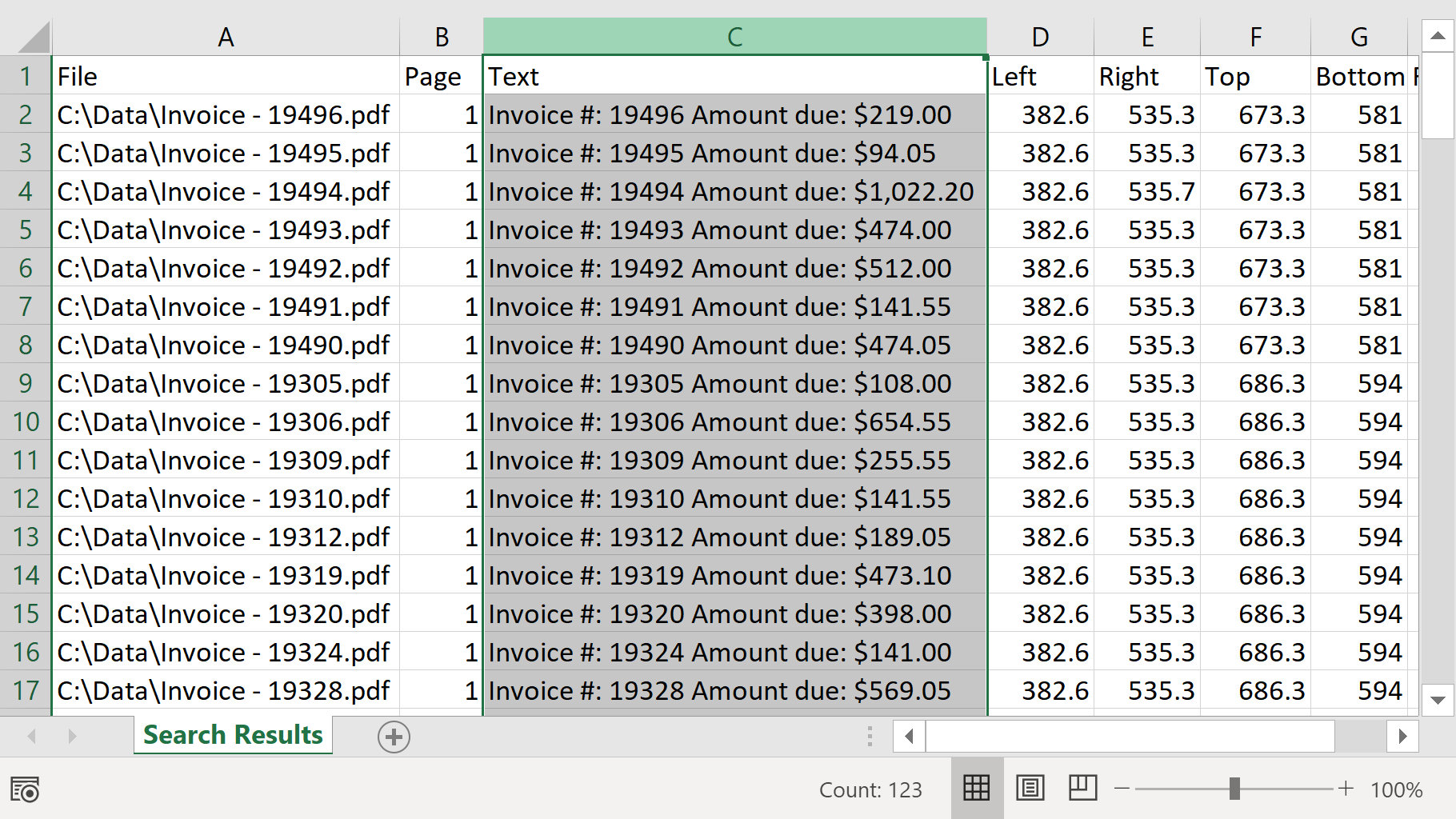
- Each text match is stored as a separate record.
- Save Search Results into a Text File ↑overview
- Alternatively, the matching text can be saved into a plain text file. Click "Extract Search Result..." link at the bottom of the "Search Results" dialog and select a text output option and press OK button:
- Select output file location and name.
- Please note that this dialog provides 3 different output file formats in the "Save as type" drop-down menu:
- Text File (*.txt)
- XML File (*.xml)
- HTML File (*.htm)
- The output text file will be automatically open in Notepad (or any other application that is designated to handle text files on your computer).
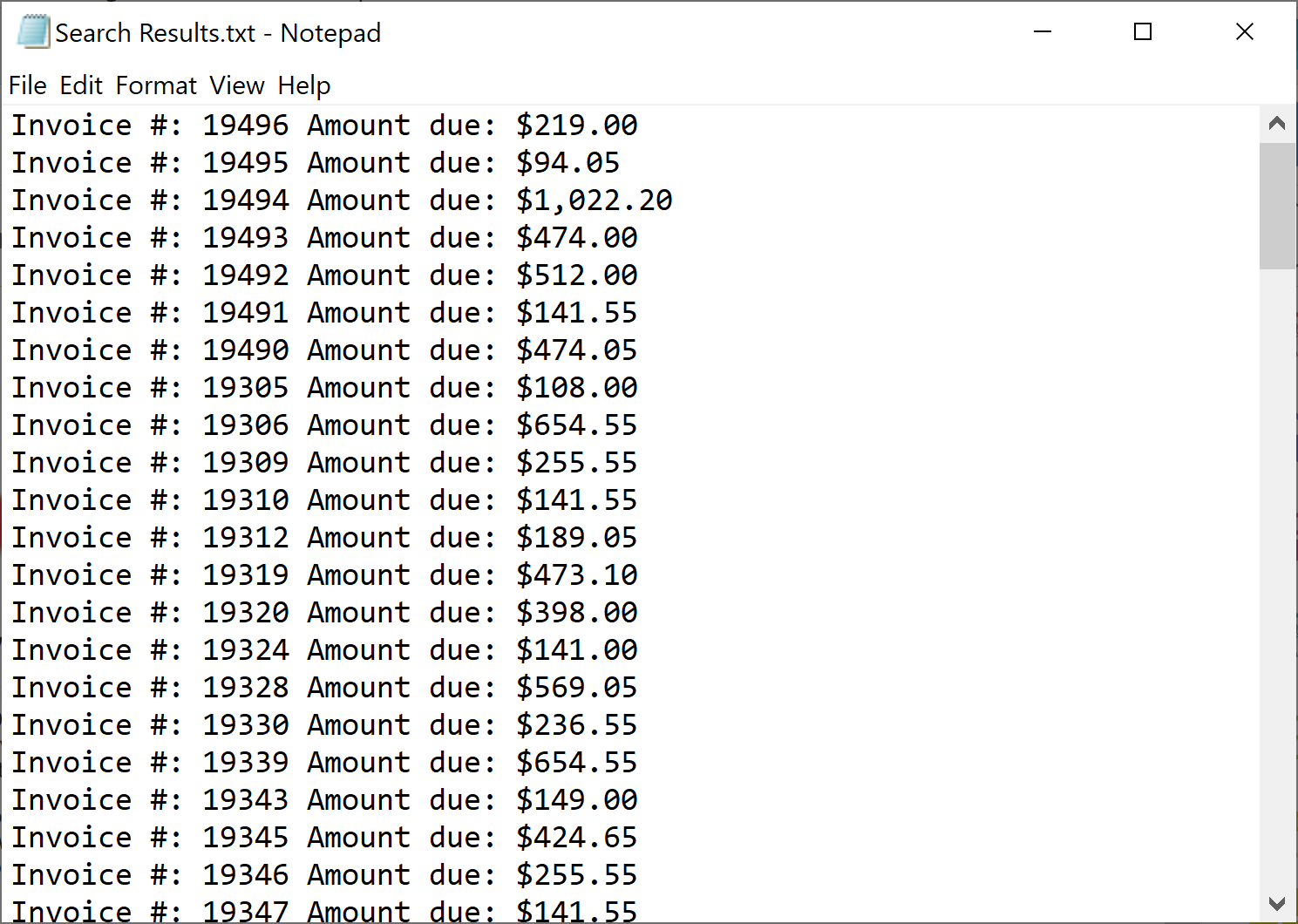
- Each text match appears on a separate line. Unlike the spreadsheet option, the text export saves only matching text and does not provide any additonal information about the search results.
Advanced: Exporting Results into Multi-Field Data Files
- Exporting as XML Data File
- The format expression can be used to export search results into multi-field data files such XML or CSV and placing each particular text field into its own data field or column. The output can be formatted as an XML data record. Use a plain text output format to save the results and use format expression to create individual data records. Make sure to select "Save as type" -> "XML File (*.xml)" in the output file selection dialog. The search results can be formated into XML records just by using a format expression:
-
Regular expression:
Invoice #: (\d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format=<invoice><id>\1\</id><amount>\2\</amount></invoice>)Sample Output: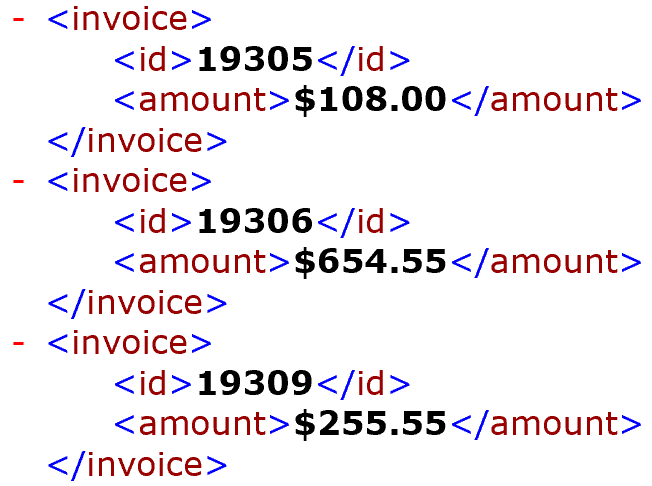
- Note that the extra \ symbol in from of < symbol in the regular expression. This is necessary to output < "as-is", not as a special character. Both < and > symbols are used to after the capturing group reference to change the case of the inserted text. For example, \1> will be replaced by an upper-case version of the capturing group 1, while \1< will be replaced with a lower case. The extra \ in front of the < is used to avoid interpreting it as case modifier.
- Exporting as CSV (Excel) File
- The following example shows how to output invoice numbers and dollar amounts as a 2-column CSV (Comma-separated values) file. Each field will be saved into a separate column to simplify further data processing. The CSV files can be directly opened by Excel or any other spreadsheet application. Make sure to use a plain text export option when saving the search results.
- The search results from the "invoice" example can be formated into CSV records by using the following expression:
-
Regular expression:
Invoice #: (\d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format="\1","\2")Sample Output: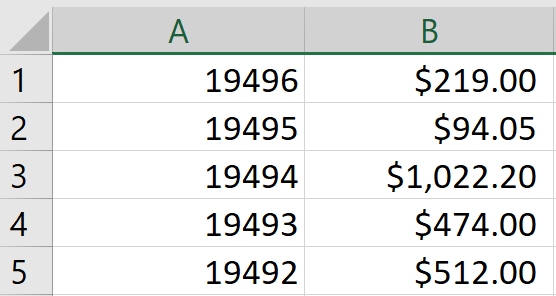
- Exporting as HTML file
- The following example shows how to format search results (invoice numbers and dollars amounts) as unordered list in HTML file.
-
Regular expression:
Invoice #: (\d+)[\s\S]+Amount due: ([$]\d+[,]?\d+[.]\d{2})(?#format=<hr><ul><li>Invoice \1\</li><li>Amount \2\</li></ul>)Sample Output: