Extacting Pages with Specific Text (Invoices by Customer Name Example)
AutoSplit plug-in for Adobe® Acrobat®
- Introduction
- It is a often necessary to extract pages from a PDF document that contain a specific search words or text patterns. That could be pages that contain client names, employer identification numbers, dates, client IDs, zip codes, social security numbers and etc. The AutoSplit™ software can easily create PDF documents by extracting pages with matching text from PDF documents and name files according to user requirements. The following tutorial is going to show how to extract invoices based on the specific customer name.
- Sample Document Description
- The sample PDF document we are going to use in this tutorial contains multiple invoices. The goal is to automatically extract pages into a new PDF document that contains the same customer name and group them into a single PDF file. For example, we are going to extract invoices for "John Doe" only.
- Splitting Approach
- Each invoice contains a client name somewhere in the invoice header. It can be used to find and extract pages that belong to the same client. We are going to use "Use Manually Defined Page Ranges" method to search input PDF document for a client name ("John Doe" in this tutorial) and group them into a single output file. The pages can be located anywhere in the input document and do not have to be in a continuous page range. This approach is preferable when the number of output documents (and text patterns) is known in advance and the pages need to be grouped based on a search criteria. The plug-in searches page text and comments, including annotations created with "Typewriter" or "Text Box" tools. All pages that contain matching text are saved into a single output document.
- Prerequisites
- You need a copy of Adobe Acrobat Standard or Professional along with AutoSplit™ plug-in installed on your computer in order to use this tutorial. You can download trial versions of both Adobe Acrobat and AutoSplit™.
- Step 1 - Open a PDF File
- Start Adobe® Acrobat® application and open a PDF file using "File > Open…" menu to open a PDF document that needs to be processed.
- Step 2 - Open “Split Document Settings” Menu
- Select Plug-ins > Split Documents > Split Document… from
the main Acrobat® menu to open "Split Document Settings" dialog.
[⚡ How to locate Plugins menu in Adobe® Acrobat® ⚡] - Step 3 - Select Splitting Method
- Check “Use manually defined page ranges” box to select a splitting method.
- Click "Add Output Document" button in the "Define Output Documents And Page Ranges" section to create a new output document definition. "Specify Page Ranges" dialog would appear on the screen.
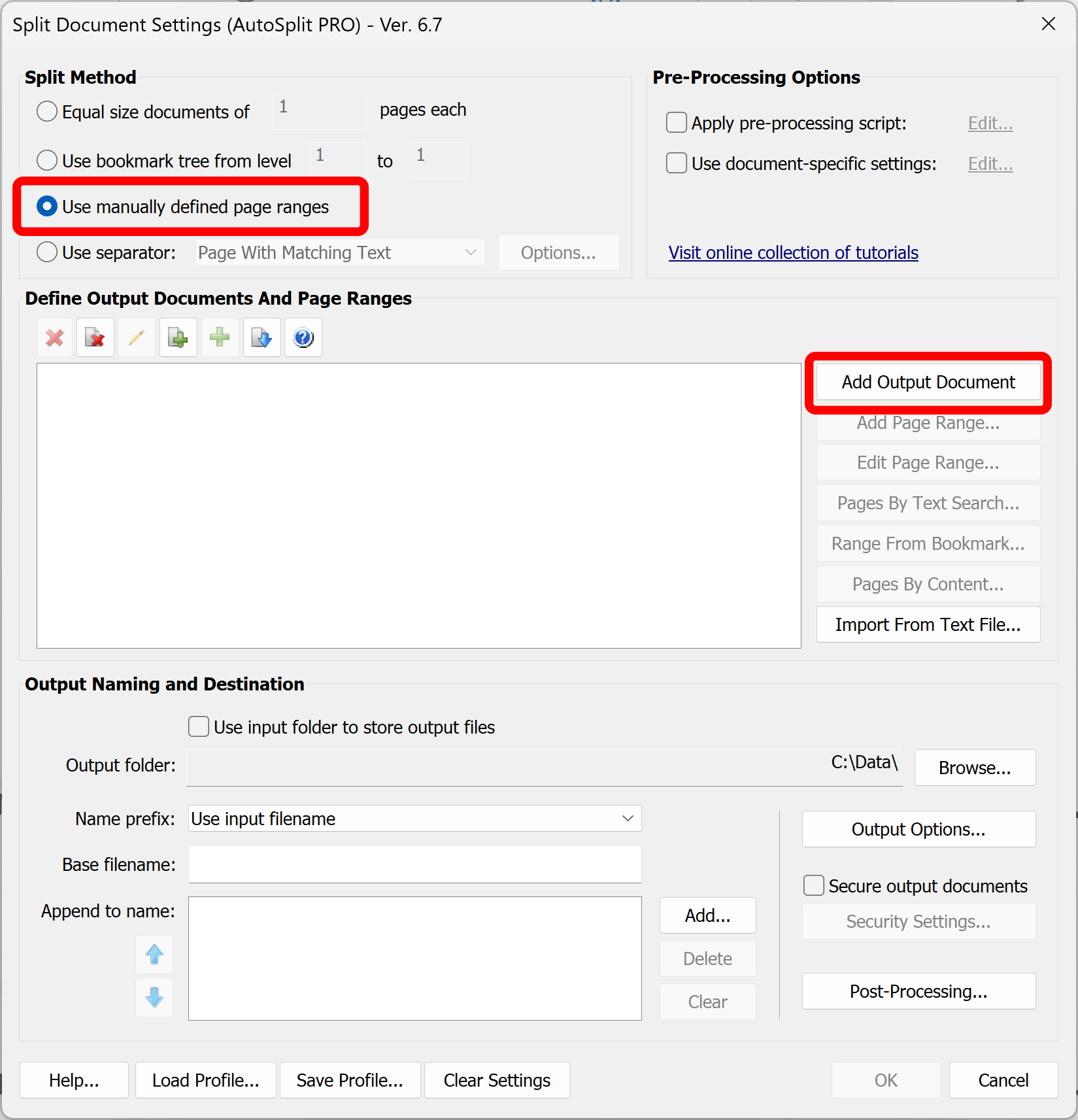
- Step 4 - Specify Page Ranges
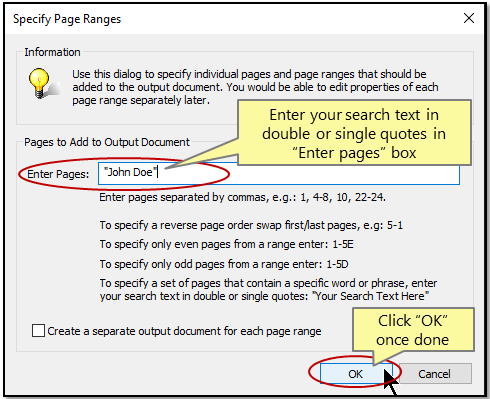
- Enter your search text in double or single quotes in “Enter pages” box to specify a set of pages that contain a specific word or phrase.
- We are going to search for "John Doe" in this tutorial.
- Click "OK" once done.
- Step 5 - Open "Output Document Options" dialog
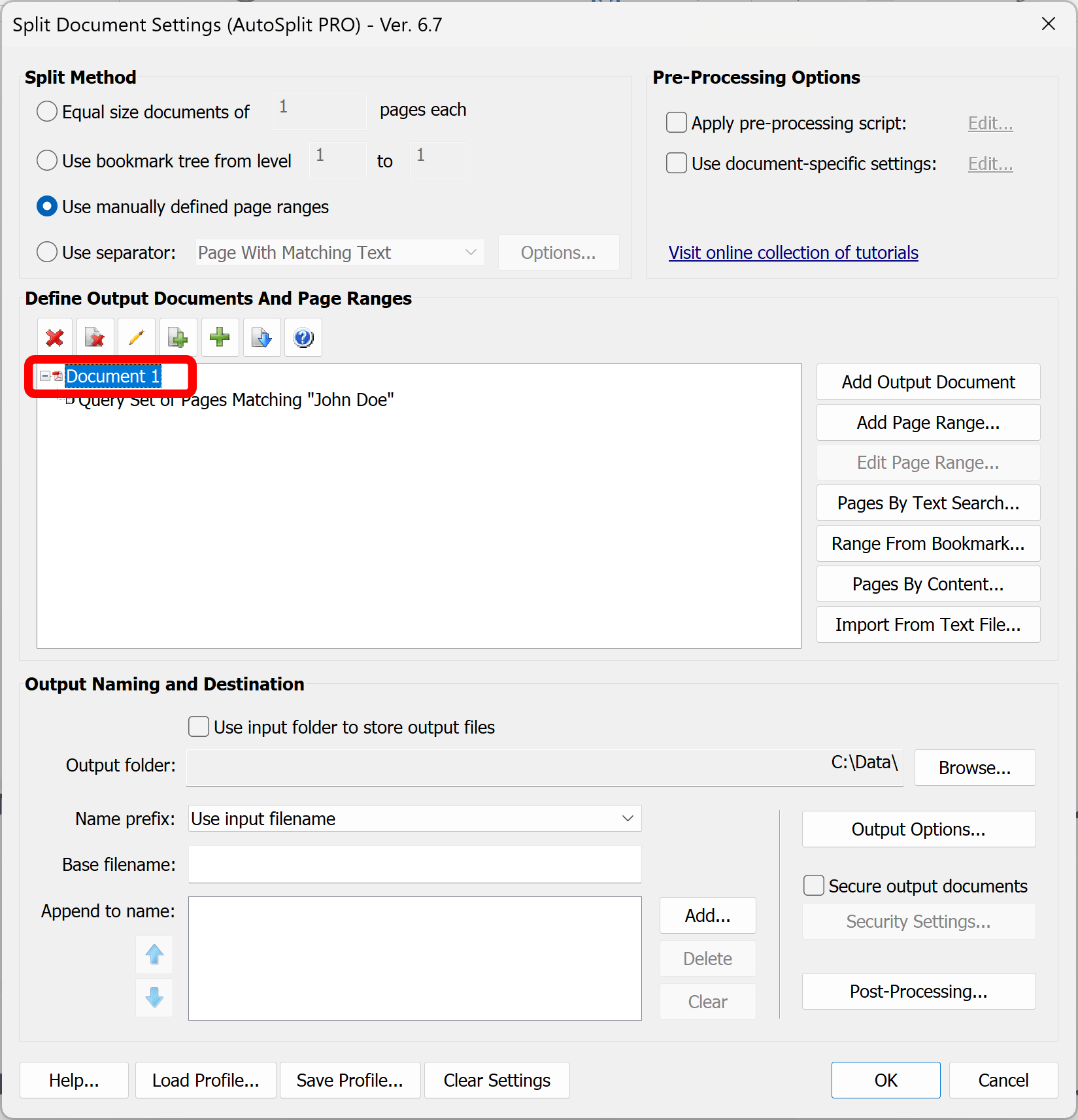
- The new document entry will be created in the output document list. By default, the output file name is set to "Document 1".
- Double click on the document name to open "Output Document Options" dialog if you want to enter a custom filename for the output document.
- Step 6 - Specify Output Filename
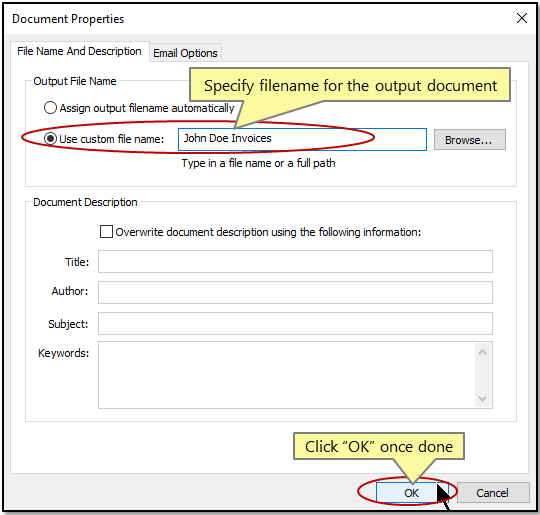
- Specify filename for the output document.
- Optionally, enter a desired metadata properties for the output document such as "Title", "Subject", "Author" and "Keywords".
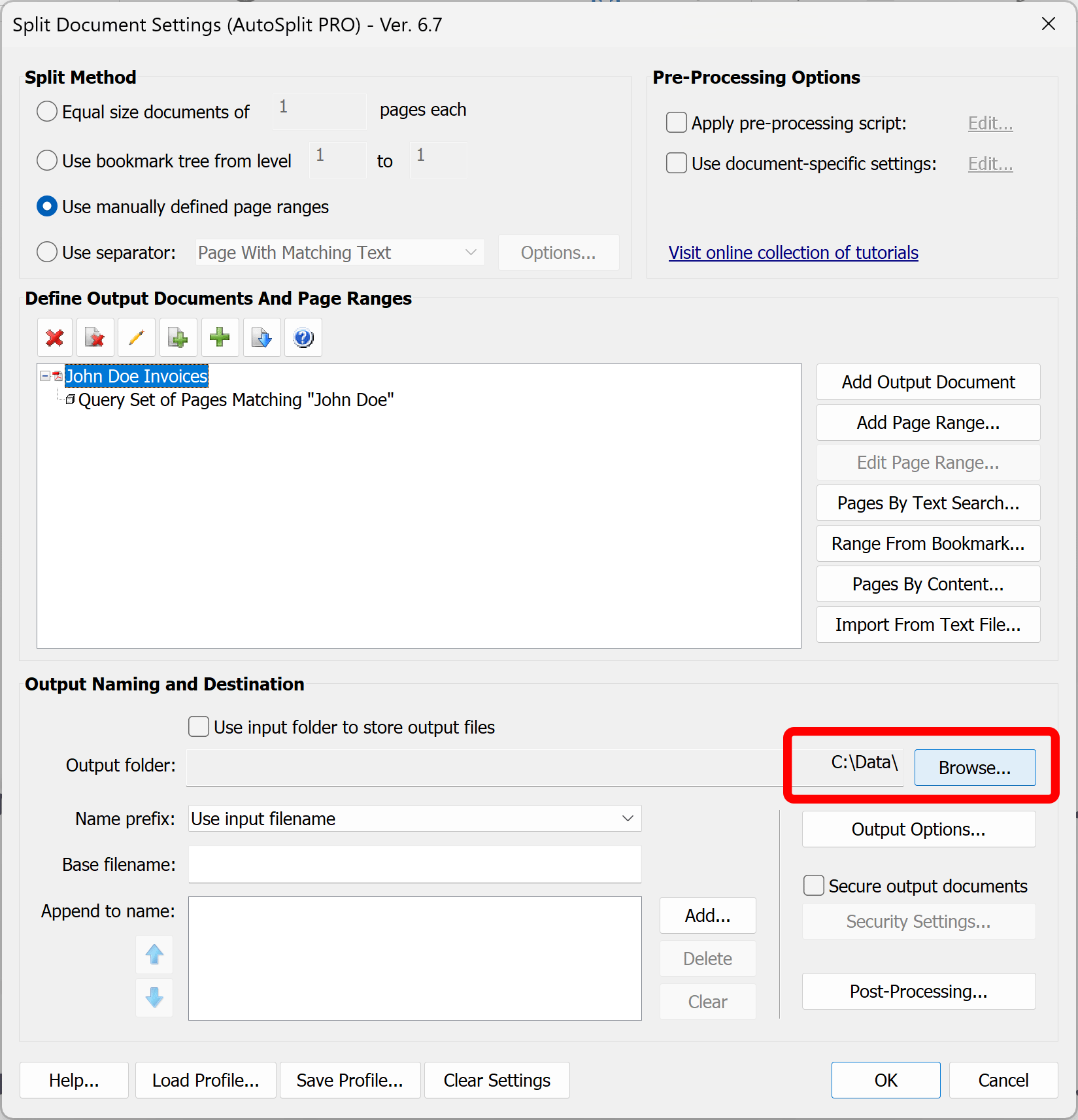
- Step 7 - Specify an Output Folder
- Specify an output folder via "Browse..." button.
- Click "OK” button to proceed.
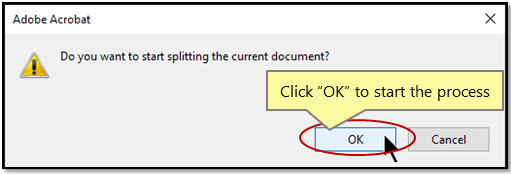
- Step 8 - Start Extacting Process
- Click “OK” in the dialog box to start the process.
- Step 9 - Examine the “AutoSplit Results” Dialog
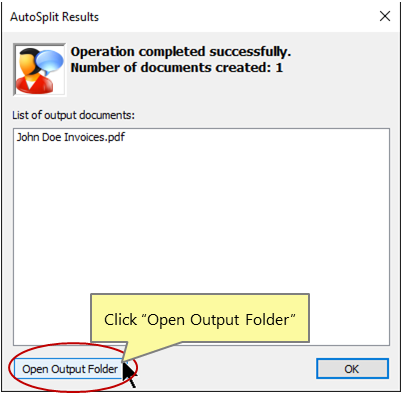
- The “AutoSplit Results” dialog appears on screen once processing is completed. It shows a list of files that have been created.
- Click “Open Output Folder” to inspect the results.
- Step 10 - Inspect the Results
- The AutoSplit plug-in has automatically extracted pages that contain "John Doe" text and saved them into a single PDF file.
