Merging Multiple PDF Files Using Control File
AutoSplit™ plug-in for Adobe® Acrobat®
Introduction
The AutoSplit™ plug-in for Adobe® Acrobat® provides a flexible way of merging multiple PDF and non-PDF files (such JPEG, TIFF, MS Word and other supported formats) into multiple PDF documents. Use Plug-ins > Merge Documents > Merge Multiple Documents Using Control File menu to merge one or more files into one or more PDF documents using a special control file. The merge control file is a plain text document that contains instructions on what document to merge (combine) and what options to use. Use any plain text editor (such as Notepad) to create this file. The minimal control file should contain instructions for the input folder(s), output folder and define a list of document to merge at least one output PDF file. There is no limit for number of output files that can be merged using this method.
Please see the following page for instructions on how to locate Plugins menu in your version
of Adobe Acrobat:
[⚡ How to locate Plugins menu in Adobe® Acrobat® ⚡]
Control File Syntax
What is a Merge Control File? ↑overview
The control file is a collection of keywords (used to define processing options) and file names. For example, the following control file produces 3 output documents (First.pdf, Second.pdf, Third.pdf) by merging 9 different files from c:\data\input folder:
inputfolder=c:\data2\input
outputfolder=c:\data2\output
File1.pdf,File2.pdf, File3.pdf,>First.pdf
File4.pdf,File5.pdf,File6.pdf,>Second.pdf
File7.pdf,File8.pdf,File9.pdf,>Third.pdf
Specifying Input and Output Folders ↑overview
Each control file should contain at least one inputfolder= and one outputfolder= instruction at the beginning of the file. You can use more than one inputfolder/outputfolder keyword to set a required input/output folders for different parts of the job. For example, you can put a separate inputfolder= keyword before each merging line to designate a different input/output folder(s).
// Enter comments or description here
inputfolder=c:\data2\input
outputfolder=c:\data2\output
File1.pdf,File2.pdf, File3.pdf,>First.pdf
inputfolder=c:\data2\input2
File4.pdf,File5.pdf,File6.pdf,>Second.pdf
Specifying Input Files ↑overview
The input files can be specified by either listing them "as-is" in a comma separated list (for example File1.pdf,File2.pdf,File3.pdf) or by using the filename= and filepath= keywords. Use the filename= keyword to specify a name of the file that is located in the currently selected input folder (specified by inputfolder= keyword). Only filename without any path should appear in the value of this keyword:
filename=File1.pdf
filename=File2.pdf
Use filepath= keyword to specify a full path to the input file. The input folder location is ignored by this keyword. You have to provide a complete path to the file:
filepath=c:\Data\File1.pdf
filepath=c:\Data\File2.pdf
Skip Missing Files ↑overview
Use skipmissing=yes and skipmissing=no keywords to control handling of the missing files. Sometimes it is necessary to designate some files as optional. If skipmissing=no is used (this is a default value), then the merge operation is not going to be performed if one of the input files are missing. If skipmissing=yes option is set, then missing files will be ignored and will not stop the merge operation from executing.
The sample code below shows how to designate some input files as optional.
filepath=c:\Data\File1.pdf
skipmissing=yes
filepath=c:\Data\OptionalDoc1.pdf
filepath=c:\Data\OptionalDoc2.pdf
skipmissing=no
Merging Files - Single Line Mode ↑overview
Each output file that needs to be merged is defined on a single text line and consists of a comma-separated list of filenames. The following example defines an output file Output.pdf that should be created by merging 3 input file: File1.pdf, File2.pdf, File3.pdf files. If file extension is omitted, the .pdf file extension is assumed and automatically added.
File1.pdf,File2.pdf,File3.pdf,>Output1.pdf
DocA.pdf,DocB.pdf,DocC.pdf,>Output2.pdf
Merging Files - Multiple Line Mode ↑overview
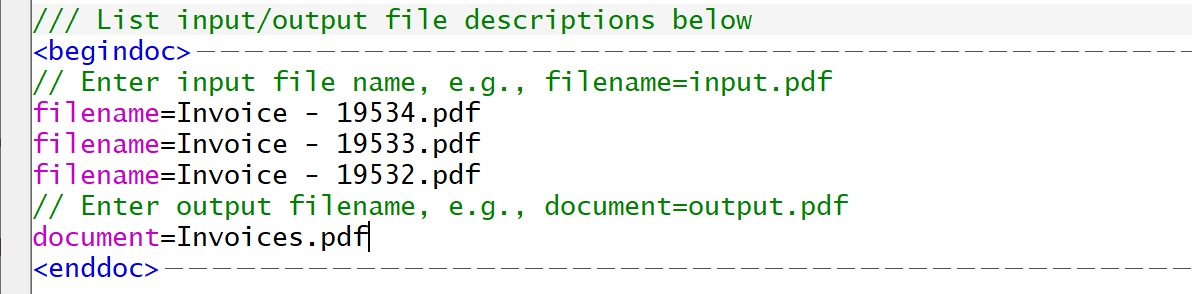
Sometimes, entering a long list of files on the single line makes the control file hard to read. Use <begindoc> and <enddoc> keywords to define a single output document on the multiple lines. The multi-line format makes code a lot more manageable.
<begindoc>
File1.pdf
File2.pdf
File3.pdf
document=Output.pdf
<endoc>
The code editor automatically displays a dashed horizontal line at the end of <begindoc> and <enddoc> keywords if they appear immideatelly at the begining of the line. The lines help to visually separate different output file definitions. The line is only displayed if the keywords appear at the start of the line. You can suppress the line separator by entering an extra space before the keyword.
Defining Output Filenames ↑overview
There are two ways how to designate an output file name for the merged file.
- By using document= keyword
- By using > symbol
The output file name is designated by > symbol and it should occur in front of the file name.
File1.pdf,File2.pdf,>Output1.pdf
File3.pdf,File4.pdf,document=Output2.pdf
If an output file name definition is ommited, then output file is created by using a name of the first file in the input file list. The following instructions will produce File1.pdf in the output folder by merging File1.pd, File2.pdf, File3.pdf from input folder:
File1.pdf,File2.pdf,File3.pdf
Merging All Files From Folder ↑overview
Use *.pdf syntax to merge all files of the specified file type from the input folder:
inputfolder=c:\data2\ProjectFiles
outputfolder=c:\data2\OutputFiles
*.pdf,>ProjectFiles.pdf
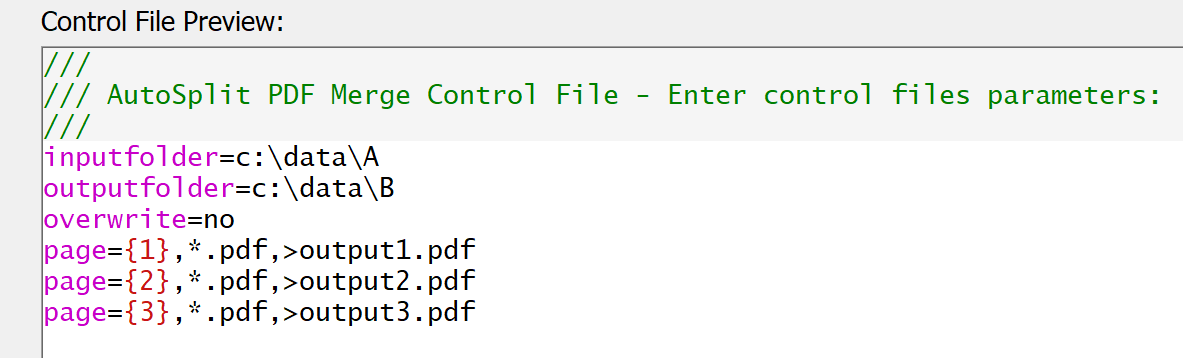
Merging By Page Numbers ↑overview
Here is an example of merging PDF files by a page number. The following script extracts the first pages from all PDF files in the input folder and puts them into output1.pdf file, the second pages are extracted into the output2.pdf, and 3rd pages from each PDF file are combined into the output3.pdf.
inputfolder=c:\data\A
outputfolder=c:\data\B
page={1},*.pdf,>output1.pdf
page={2},*.pdf,>output2.pdf
page={3},*.pdf,>output3.pdf
Using Wildcards to Select a Group of Files ↑overview
Use filter= keyword along with wildcards to select multiple files that match a specific naming scheme. The following instructions will merge all PDF files from a folder (and all its sub-folders) that start with "Invoice":
inputfolder=c:\data\input
outputfolder=c:\data
subfolders=yes
filter=Invoices*.pdf,>ProjectFiles.pdf
Specifying Sorting Order ↑overview
Optionally, specify sorting order of the files from the folders by using sortorder keyword:
sortingorder=ascending
*.pdf,>ProjectFiles.pdf
Searching for Files in Subfolders ↑overview
The following code will search for files CoverPage1.pdf and CoverPage2.pdf inside the c:\data\input folder and all its subfolders to use with the merge:
inputfolder=c:\data\input
outputfolder=c:\data
subfolders=yes
filter=CoverPage1.pdf,filter=CoverPage2.pdf,>ProjectFiles.pdf
Merging non-PDF files ↑overview
The following examples merges all Microsoft Word files (with *.doc and *.docx extensions) from input folder into Report.pdf. All file types supported by Adobe Acrobat can be merged. The actual list of supported formats (for conversion to PDF) may differ depending on Acrobat version. Use "Edit > Preferences..." menu to review or configure format conversion settings.
inputfolder=c:\data2\ProjectFiles
outputfolder=c:\data2\OutputFiles
*.doc,*.docx>Report.pdf
Creating Report File ↑overview
The merge process creates a report file that lists all input and output files as well as any errors encountered during the processing. Report file is generated in HTML format and can be viewed in any browser.
Selecting a Page Range ↑overview
Many keywords can be applied to multiple files at once if a wildcard file selection is used. Use pagerange= keyword to specify a page range to be extracted from the input file. Only pages specified by the pagerange keyword are included into the merged output. Here is an example of using pagerange= keyword that is applied to all PDF files in the input folder. Keyword selects first 10 pages from each input document for using in the merge operation:
inputfolder=c:\data\input
outputfolder=c:\data
subfolders=yes
pagerange=1-10,*.pdf,>ProjectFiles.pdf
Merging Specific Page Ranges ↑overview
The following example shows how to merge only specific page ranges from each input PDF document. The following example merges pages 1-3 from File1.pdf, pages 4-5 from File2.pdf, and pages 1-6 from File3.pdf.
inputfolder=c:\data\input
outputfolder=c:\data\output
overwrite=no
<begindoc>
pagerange=1-3,File1.pdf
pagerange=4-5,File2.pdf
pagerange=1-6,File3.pdf
document=MergedDocument.pdf
<enddoc>
There is also a page= keyword for extracting just a single page from the input document. The following code will extract page 5 from File1.pdf and save it as SinglePageExtract.pdf:
<begindoc>
page={5},File1.pdf
document=SinglePageExtract.pdf
<enddoc>
Using Bookmarks to Refer to Pages ↑overview
The pagerange= and page= keywords provide a way to use page labels, named destinations and bookmarks names to refer to pages. The following code illustrates how to extract a page range defined by two bookmarks - FirstPage andLastPage:
pagerange={b:FirstPage}-{b:LastPage},File1.pdf,>ExtractByBookmarks.pdf
It is recommended to use {...} syntax when defining a page reference. The text inside brackets can contain any character or digit except a newline and a dash.
IfFirstPage bookmark points to page 5, andLastPage bookmark points to page 8, then the above code is equivalent to extracting pages 5-8 from the File1.pdf and saving them as the ExtractByBookmarks.pdf.
Copying Bookmarks
Use copybookmarks=yes and copybookmarks=no to enable/disable copying bookmarks from input documents to output document. You can control depth of the bookmarks being copied by using copybookmarkstolevel= keyword. For example, use copybookmarkstolevel=2 to copy only first two bookmarks levels. Use copybookmarks=0 to copy all levels. By default, bookmark copying is enabled for all bookmark levels.
Specifying Bookmark Indent
Use bookmarkindent= keyword to specify a desired level of bookmark indentation for the next input document(s). This keyword will affect bookmarks hierarchy in the merged document and appearance of table of contents (if table of contents option is used).
For example, use bookmarkindent=2 to insert next document(s) bookmarks at the second level from the bookmark root. Note, that there should be level 1 bookmarks already in the document. It is not possible to insert bookmark at the level that does not have a "parent" bookmark. The top level bookmark uses bookmarkindent=0.
Inserting Bookmarks
Use insertbookmark= keyword to insert a custom bookmark into the merged file. The bookmark is not going to point to any page, and will serve as grouping/chapter bookmark for the bookmark that follow. Use this keyword together with bookmarkindent= keyword to create a heirarchical bookmark structure or table of contents.
For example, use insertbookmark=Performance Overview to insert Performance Overview bookmark into a current output document.
Using Destinations and Page Labels ↑overview
The following code shows how to use named destinations (d: prefix) and pagel labels (l: prefix) in the pagerange= keyword.
pagerange={d:DestinationA}-{d:DestinationB},File1.pdf,>ExtractByDestination.pdf
pagerange={l:A525}-{l:A538},File1.pdf,>ExtractByPageLabels.pdf
Page label is a custom name/alias that can be assigned to a PDF page to better reflect a logical structure of the document. Page labels can be assigned in thePage Thumbnails pane of Adobe Acrobat. Page label can be any combination of symbols, not only a number. For example, Roman numerals are frequently used as page labels (ii, vii, xii).
Using Last keyword ↑overview
Use Last keyword to refer to the last page in the PDF document:
pagerange={1}-{Last},File1.pdf,>ExtractByDestination.pdf
page={Last},File1.pdf,>ExtractByPageLabels.pdf
Interleaving Pages From Multiple Documents ↑overview
Use interleavepages=yes keyword to set document merging into a page interleaving mode. In this mode, output document is generating by repeatedly taking a specified number of pages from each document (use numpagestointerleave keyword) and placing them into the output. For example, if we have 3 input documents (A.pdf, B.pdf, C.pdf) and merging them in page interleaving mode (while specifying numpagestointerleave value as 1, 2, 3 pages correspondingly), then the output document will contain the following pages:
- Page 1 from A.pdf
- Pages 1-2 from B.pdf
- Pages 1-3 from C.pdf
- Page 2 from A.pdf
- Pages 3-4 from B.pdf
- Pages 4-6 from C.pdf
- ...
Here is a corresponding control file settings for the above example:
interleavepages=yes
<begindoc>
numpagestointerleave=1
filename=A.pdf
numpagestointerleave=2
filename=B.pdf
numpagestointerleave=3
filename=C.pdf
document=InterleavedPages.pdf
<enddoc>
Use interleavepages=no keyword to turn page interleaving mode off.
Use duplicatepagesinterleave=yes to restart page inserting from the start of the document that does not have enough pages to interleave. For example, if we are interleaving pages from document A.pdf (10 pages, 2 pages to interleave) and document B.pdf (2 pages, 1 page to interleave), then output is going to look like the following if this option is turned on:
- Page 1-2 from A.pdf
- Page 1 from B.pdf
- Pages 3-4 from A.pdf
- Page 2 from B.pdf
- Pages 5-6 from A.pdf
- Page 1 from B.pdf
- Pages 7-8 from A.pdf
- Page 2 from B.pdf
- Pages 9-10 from A.pdf
- Page 1 from B.pdf
Specifying Page Display Mode ↑overview
Use pagemode keyword to specify how the output document is going to be displayed in the page view. There are 7 possible values:
- 0 - Leaves the view mode as is
- 1 - Displays the document, but displays neither Pages panel nor bookmarks.
- 2 - Displays the document and Pages panel.
- 3 - Displays the document and Bookmarks panel.
- 4 - Displays the document in full-screen viewing mode.
- 5 - Not used
- 6 - Displays the document and Layers panel
- 7 - Displays the document and Attachments panel.
The following instructions will create an output PDF file that shows a document and Bookmarks panel.
pagemode=3
<begindoc>
filename=A.pdf
filename=B.pdf
document=Output.pdf
<enddoc>
Custom Processing with Acrobat JavaScript ↑overview
Use script keyword to specify Acrobat JavaScript code to execute on the output document. Whole script should be entered on a single line. If you need to use a multi-line script, then use scriptfile keyword.
The following script will delete all pages from output document that does not have any searchable text. Make sure to enclose script code in double-quotes.
script="for (var i = this.numPages-1; i >= 0; i--) { if (this.getPageNumWords(i) == 0) this.deletePages(i,i); }"
Alternatively, if you need to use a larger script, then use scriptfile keyword and specify a full path to the text file that contains Acrobat JavaScript code.
scriptfile=C:\Data\DeleteBlankPages.js
Scripting Example: Inserting Pages At Specific Position ↑overview
The following example shows how to merge two documents A and B. Document A can have any number of pages, while document B has only one page. Document B needs to be inserted as 4th page from the end of the resulting document. The approach is to merge documents A and B in a regular way and then use script to move a last page (representing document B) as a 4th page in the document. Note that page numbers in Acrobat JavaScript is 0-based (first page is 0).
inputfolder=c:\data\input
outputfolder=c:\data\input
<begindoc>
filename=A.pdf
filename=B.pdf
script="dest=this.numPages-5; this.movePage(this.numPages-1,dest);"
document=Output.pdf
<enddoc>
Generating Table of Contents ↑overview
Use "createtoc=yes" and "createtoc=no" keywords to control automatic generation of table of contents. Table of contents is created from filenames and bookmarks.
Optionally, use tocstyle keyword to load a custom style settings from a *.tocmerge file.
createtoc=yes
tocstyle=c:\data\TOCSettings.tocmerge
Use "Plug-ins > Merge Documents > Merge Documents into Single Document" menu to create and save TOC settings into a *.tocmerge file. TOC-related options are available via "Table of Contents Options..." link.
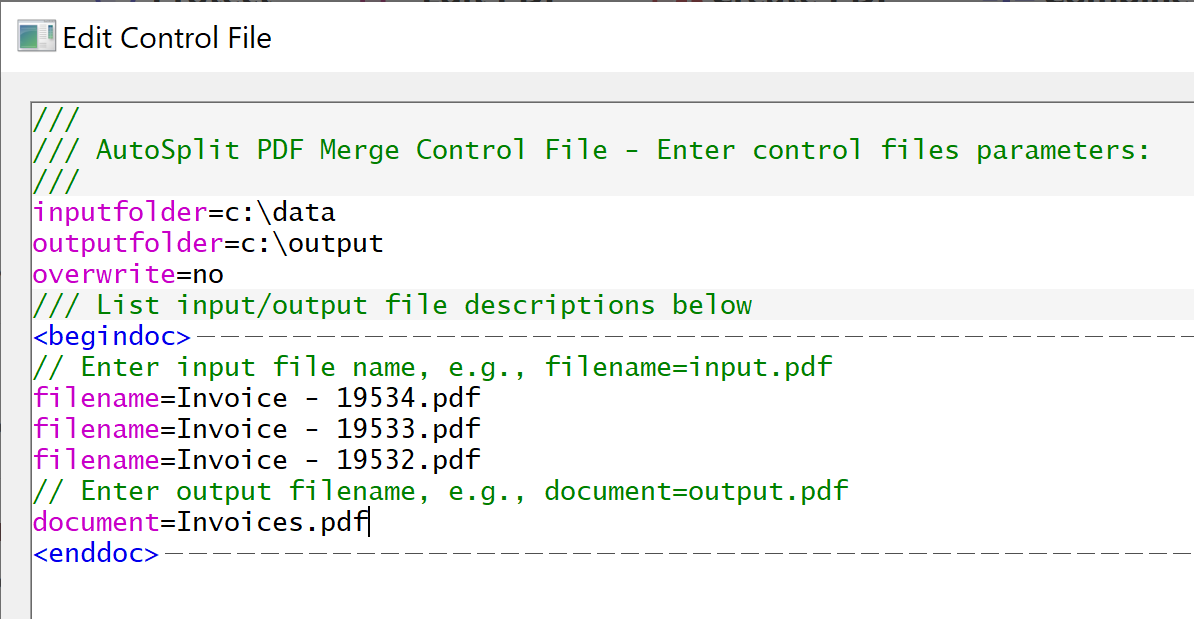
Entering Comments ↑overview
Use // to enter comments. Comments are ignored during the processing and are used for adding readable annotations to the control instructions.
// Enter comments or description here
Use /// to enter comments that appear on the gray-colored background for a better visual apperance. Use this kind of comments to separate different parts of the control file.
List of Supported Keywords ↑overview
| Keyword | Definition | Examples |
|---|---|---|
| author | Sets "Author" metadata record for the output document. This keyword can be used multiple times. It affects all merged documents that follows the keyword. It needs to be specified on a separate line only. Do not use commas in the text of this field. | author=Acme Consulting Inc. |
| bookmark | Defines a bookmark to use for bookmarking of a specific input file in the output document. This instruction needs to be specified before the name of the input file. By default, all sub-documents are bookmarked using input file name. | Bookmark=First Document,File1.pdf,Bookmark=Second Document,File2.pdf |
| bookmarkindent | Sets bookmark level (indentation) for the next input document(s). Use 0 for the top-most level. Bookmarks hierarchy in t | bookmarkindent=2 |
| copybookmarks | Controls the transfer of the bookmarks from input documents to the output. | copybookmarks=yes copybookmarks=no |
| copybookmarkstolevel | Controls depth of the bookmarks copied from input documents to the output. | copybookmarkstolevel=2 - copies only first two levels of bookmarks copybookmarkstolevel=0 - copies all levels of bookmarks |
| createtoc | Generates table of contents for the output document from bookmarks. | createtoc=yes createtoc=no |
| document | Specifies the name of the output file. | document=OutputDocument.pdf |
| duplicate | Inserts multiple copies of the same document. Default value is 1. Maximum value is 100. | duplicate=10,File1.pdf |
| duplicatepagesinterleave | Restart page counting from the start if there are not enough pages to interleave. See interleavepages keyword. Affects all documents in the current merge operation. | duplicatepagesinterleave=yes |
| evenpagesonly | Specifies that only even pages should be used from the next input PDF document. This instruction should appear before an input document entry and affects only the next input file. The only supported value is yes. | evenpagesonly=yes,File1.pdf |
| extractnth | Specifies that only Nth pages from the next input document need to be extracted. For example, setting this value to 2 will extract pages 1, 3, 5, 7, 9and so on. Setting this value to 3 will extract pages 1, 4, 7, 10 and so on. This value cannot be less than 1. This instruction should appear before an input document entry and affects only the next input file. | extractnth=2,File1.pdf |
| filename | Specifies an input filename without any path. File is located in the folder specified by inputfolder= keyword. | filename=File1.pdf |
| filepath | Specifies a full path to the input file. | filepath=c:\Data\Project\File1.pdf |
| filter | Defines a file name filter. Use wildcards and ? symbol to specify multiple files that match a specific file naming pattern. Can be used to search for a file inside subfolders (if subfolder=yes keyword is set). | filter=Invoices*.pdf filter=*.pdf filter=CoverPage1.pdf |
| flattenforms | Turns form flattening in the output. If form flattening is used, then all interactive form fields, annotations and buttons will be converted into regular PDF text and graphics. | flattenforms=yes flattenforms=no |
| inputfolder | Defines an input folder where input files are located. This keyword is required. There should be at least one keyword in the begining of the control file. This instruction can be used multiple times anywhere in the control file. | inputfolder=C:\Data\Input |
| insertbookmark | Insert a custom bookmark into the current output file. Bookmark is not going to point to any pages in the document and is used for bookmark grouping purposes. | insertbookmark=Performance Overview |
| interleavepages | Sets merging into a page interleaving mode. In this mode, output document is generating by repeatedly taking a specified number of pages from each document. | interleavepages=yes |
| keywords | Sets "Keywords" metadata record for the output document. This keyword can be used multiple times. It affects all merged documents that follows the keyword. It needs to be specified on a separate line only. Do not use commas in the text of this field. | Keywords=Keyword1 Keyword2 Keyword3 |
| numpagestointerleave | Specifies number of pages to interleave from the document when using page interleave mode (see interleavepages) | numpagestointerleave=2 |
| oddpagesonly | Specifies that only odd pages should be used from the next input PDF document. This instruction should appear before an input document entry and affects only the next input file. The only supported value is yes. | oddpagesonly=yes,File1.pdf |
| outputfolder | Defines an output folder where to place merged documents. This keyword is required. There should be at least one keyword in the begining of the control file. This instruction can be used multiple times anywhere in the control file. | outputfolder=C:\Data\Output |
| overwrite | This keyword is used to define if output files needs to be overwritten if a file with the same name already exists in the output folder. This option is global and should be specified once per control file. | overwrite=yes overwrite=no |
| padtoeven | Turns on automatic padding of each input file with a blank page if a number of pages in the document is odd. Use padtoeven=yes to turn ON padding, padtoeven=no to turn it OFF. This instruction can be used anywhere in the control file.Please note that there is no space neither before or after = symbol. | padtoeven=yes padtoeven=no |
| page | Defines a single page to use from the next input document. | page=1,File.pdf // Using bookmark name to point to a page page={b:Introduction},File.pdf |
| pagemode | Sets a page display mode (page only, page and bookmarks pane, page and layers, etc) | pagemode=1 |
| pagerange | Defines a page range to use from the next input document. Format: pagerange=StartingPageNumber-EndingPageNumber. Page numbering starts from 1. Specify 0 to indicate the last page of the document. This instruction should appear before an input document entry and affects only the next input file. | pagerange=1-2,File1.pdf pagerange=10-0,File1.pdf // Use b: prefix to specify pages via bookmarks pagerange={b:First Chapter}-{b: Second Chapter},File1.pdf // Use d: prefix to specify pages via destinations pagerange={d:A5}-{d:B1},File.pdf // Use l: prefix to specify pages via page labels pagerange={l:iiv}-{l:vii},File.pdf // Use "Last" keyword to refer to a last page in the document pagerange={10}-{Last},File.pdf |
| password | Password protects output file. This instruction should occur on the same line with the list of the input files and defines a password to use to secure output document. | File1.pdf,File2.pdf,password=3kf8f81$! |
| portfolio | This keyword is used to select between creating a regular output PDF file or PDF portfolio. It affects all merged documents that follows the keyword. It needs to be specified on a separate line only. The default value is portfolio=no and creates regular PDF files as output. | portfolio=yes portfolio=no |
| renamefields | Controls how form fields are merged into the output document. If this option is ON, then form fields are renamed to avoid name collision and preserve data. In PDF file format, all form fields with the same name automatically share the same value. If two files with identical fields are merged together, they will automatically share the values from the first file, and the data from other files will be lost. | renamefields=yes renamefields=no |
| report | Controls generation of the HTML report file. Report file contains all details about input and output files, as well as any errors encountered during the processing. By default, report generation is turned on. | report=yes report=no |
| reportfile | Specifies a full path with filename for the report document. Report file contains all details about input and output files, as well as any errors encountered during the processing. Report file is produced in HTML format and should have *.htm file extension. | reportfile=C:\Project\Reports\ProcessingLog.htm |
| script | Run Acrobat JavaScript code on the output PDF file. Script should fit on a single line of text. | script="Enter code here" |
| scriptfile | Load Acrobat JavaScript code from a specified text file and run it on the output file. | scriptfile=C:\Data\DeleteBlankPages.txt |
| skipmissing | Controls how missing files are handled. | skipmissing=yes filename=OptionalDocument.pdf skipmissing=no |
| sortorder | Defines a sorting order for the files from a folder when using wildcards such as *.pdf. | sortorder=ascending sortorder=descending |
| subfolder | Use this keyword to include files from subfolders, when using file name templates such as *.pdf. | subfolders=yes subfolders=no |
| subject | Sets "Subject" metadata record for the output document. This keyword can be used multiple times. It affects all merged documents that follows the keyword. It needs to be specified on a separate line only. Do not use commas in the text of this field. | subject=Account Statement |
| title | Sets "Title" metadata record for the output document. This keyword can be used multiple times. It affects all merged documents that follows the keyword. It needs to be specified on a separate line only. Do not use commas in the text of this field. | title=Account Terms And Conditions |
| tocstyle | Sets path to a table of contents settings file. | tocstyle=c:\data\TOCSettings.tocmerge |
Here is an example of the control file that uses most keywords:
inputfolder=c:\data2\input
outputfolder=c:\data2\output
reportfile=c:\data2\ReportLog.htm
overwrite=no
padtoeven=yes
author=Acme Consulting LLC
title=Customer Account Statement
subject=Second Quarter 2013
keywords=Account Second Quarter
pagerange=1-5,File1.pdf,File2.pdf, File3.pdf,>First.pdf
bookmark=First Document,File4.pdf,bookmark=Second Document,File5.pdf,bookmark=Third
Document,File6.pdf,>Second.pdf
pagerange=2-3,File7.pdf,pagerange=1-1,File8.pdf,pagerange=2-2,File9.pdf,>Third.pdf,password=ab1492t%