Recognize Text in Scanned PDF Documents
Adobe® Acrobat® DC Tutorial
Introduction
This tutorial shows how to make scanned PDF documents searchable using "Recognize Text" operation available in the Adobe® Acrobat® software. Originally, the scanned PDF documents do not contain any searchable text. Each page is just an image. The "Recognize Text" operation (also known as "Optical Character Recognition" or OCR) processes each page and creates an invisible layer of text that can be searched or copied and pasted into a new document. The searchable text is added behind the page image, so the visual appearance of the pages does not change.
Why Recognize Text?
If the document does not have any searchable text, then it significantly limits its functinality. The document cannot be used for any text-based processing such as automated bookmarking and linking, text search and extraction, keyword-based redacting and etc.
Is my PDF searchable?
Open the PDF document in the Adobe® Acrobat® and try to select any text on the page with a selection tool. If you can highlight a text string and copy/paste it into a text editor (such as the Notepad, Microsoft Word or Outlook), then the document does contain a searchable text. If you cannot highlight a text on the page, then the document is not searchable.
.PNG)
Scanning Quality
To apply "Recognize Text" operation to a PDF, the original scanner resolution must have been set at 72 dpi or higher. Note that scanning at 300 dpi produces the best text for conversion. At 150 dpi, OCR accuracy is slightly lower.
Prerequisites
You need a copy of the Adobe® Acrobat® installed on your computer in order to use this tutorial. You can download a trial version of the Adobe® Acrobat®.
Acrobat Versions
Different versions of Adobe Acrobat can vary significantly in their visual interface, layout, and available tools. As a result, the steps required to complete a task may differ depending on which version is being used. Features might appear in different menus, icons may look different, and some functions may even be renamed or relocated. Because of these variations, users often need to adjust their workflow or follow version-specific instructions to ensure they can process documents correctly.
- Instructions for "new" Adobe Acrobat interface
- Instructions for "classic" Adobe Acrobat (2022 and older)
Instructions for "New" Adobe Acrobat
Step 1 - Open a PDF Document
Start the Adobe® Acrobat® application and use "Menu > Open..." menu to open a scanned PDF document.
Step 2 - Start the "Scan & OCR" Tool
Use All Tools toolbar to double-click on Scan & OCR tool.
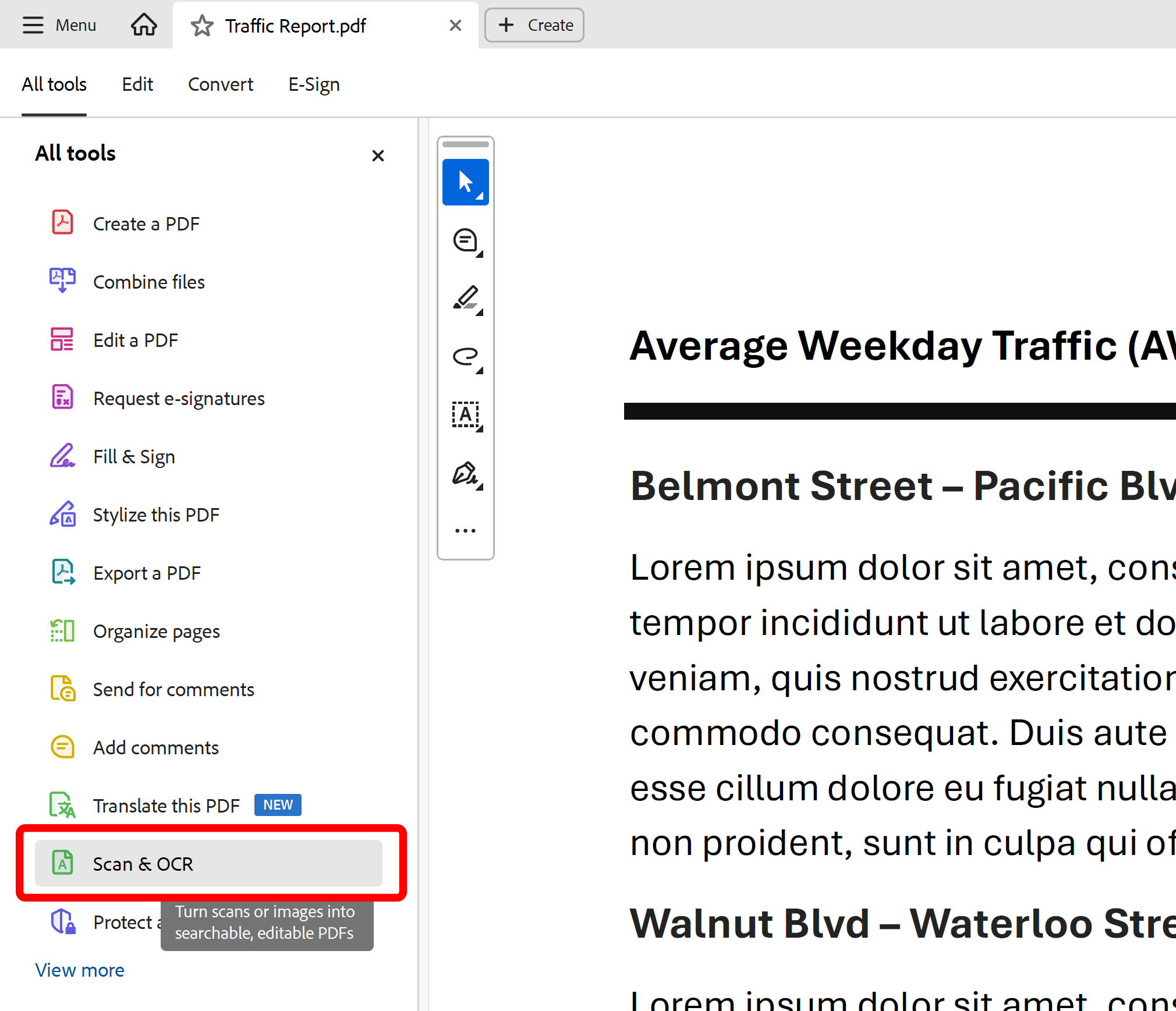
Step 3 - Select Recognize Text Tool
Select In this file option under Recognize Text section.
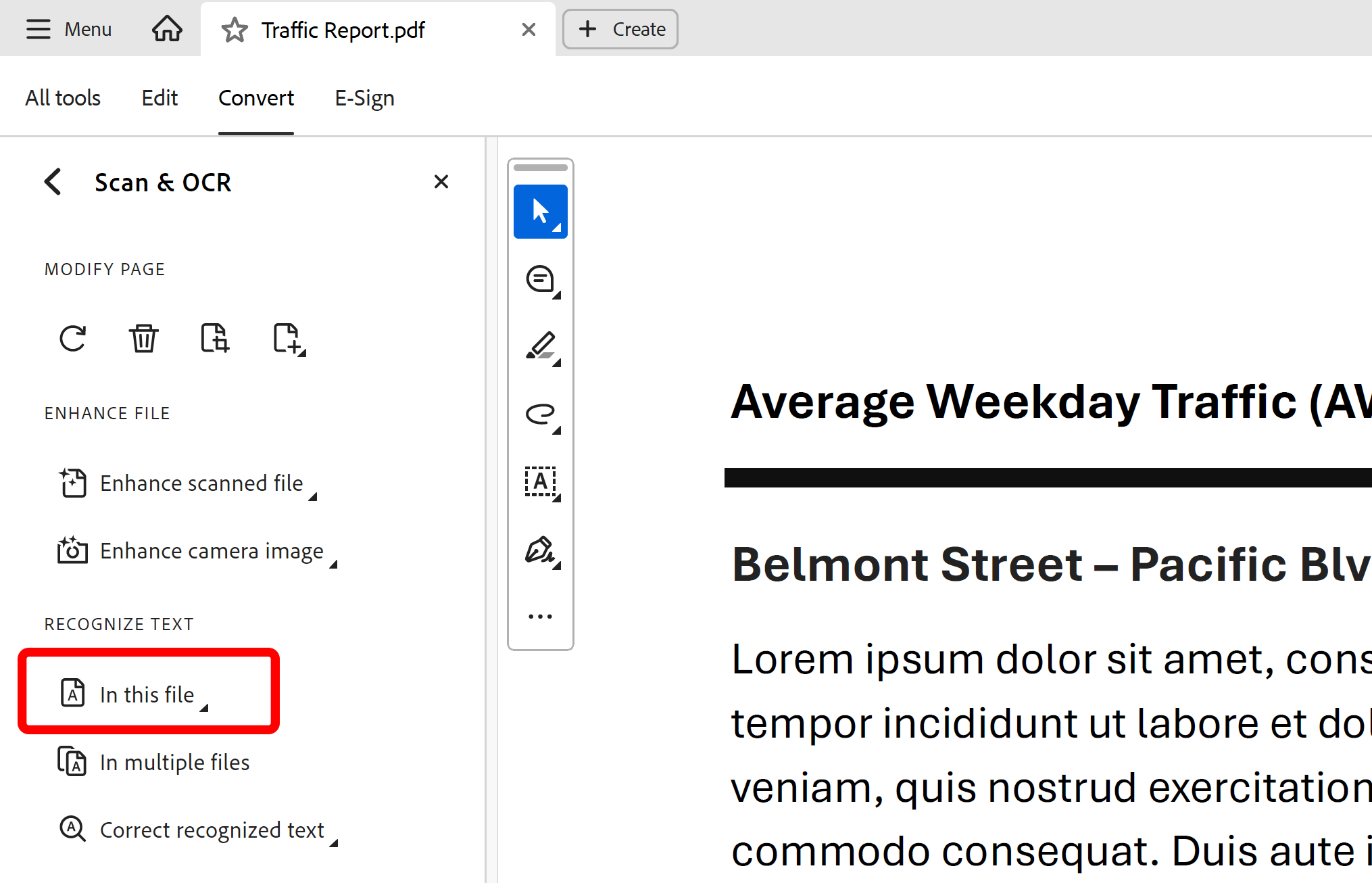
Step 4 - Adjust Settings (Optional)
Optionally, adjust settings. It is rarely necessary and it is safe to use the defaults. Otherwise, skip to the next step.
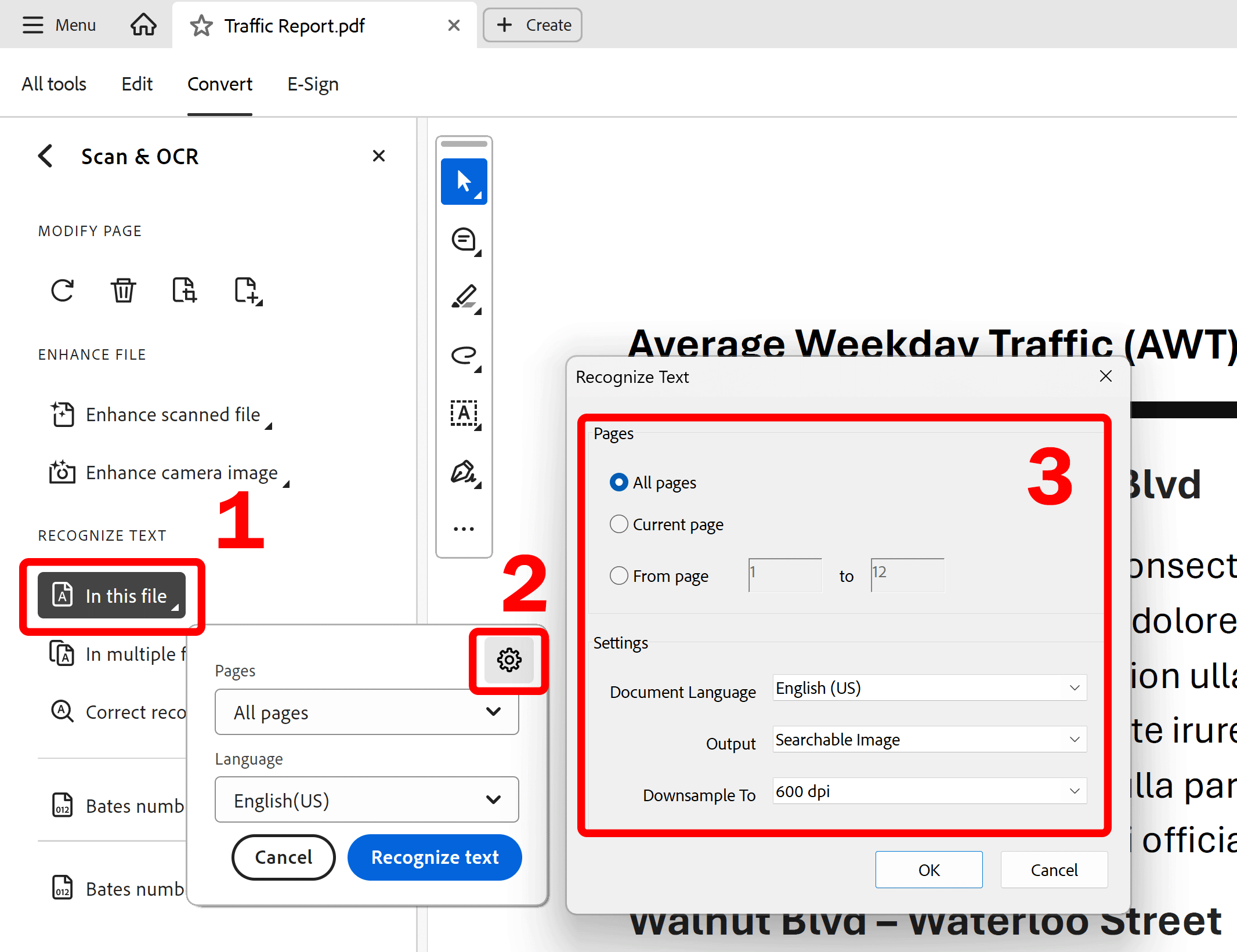
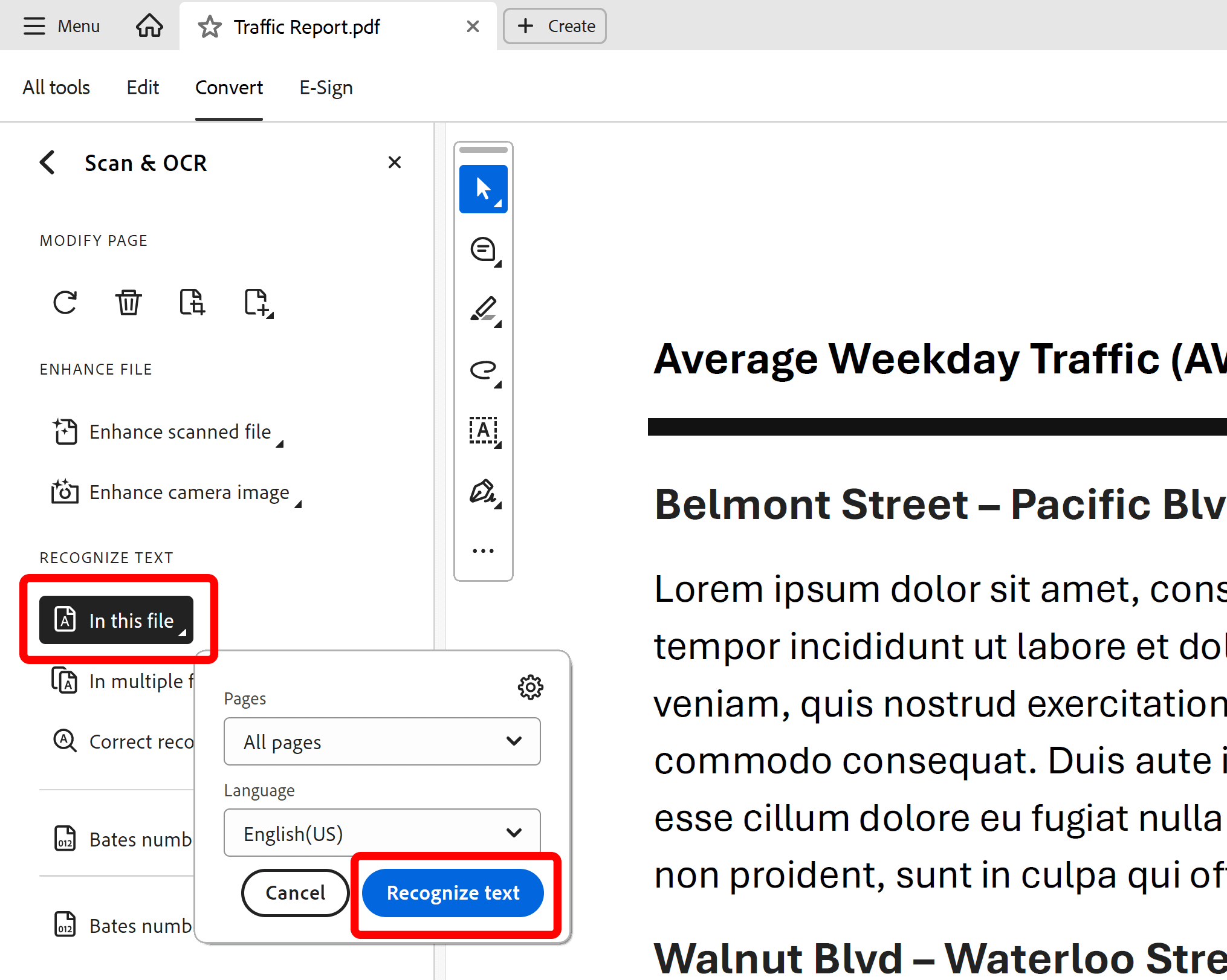
Step 5 - Run Processing
Press Recognize Text button to run text recognition on the current PDF document. Once processing is finished, the document will be searchable.
Instructions for "Classic" Adobe Acrobat
Step 1 - Open a PDF Document
Start the Adobe® Acrobat® application and use "File > Open..." menu to open a scanned PDF document.
.PNG)
Step 2 - Start the "Enhance Scans" Tool
Select the "Tools" from the main toolbar. Double click on the "Enhance Scans" tool.
.PNG)
Step 3 - Select a PDF Document(s) to Be Processed
Expand the "Recognize Text" pull down menu. Select "In This File" to process a currently opened PDF document. Optionally, click "In Multiple Files..." to select multiple PDF files or folder to process.
.PNG)
Step 4 - Specify Settings
The "Recognize Text" options are displayed in the second-level toolbar. Select a page range and language for the text recognition. Optionally, click "Settings" to open the "Recognize Text" dialog box, and specify the options as needed.
.PNG)
The "Recognize Text" dialog box allows to specify general settings for OCR.
Specify the language for the OCR engine to use to identify the characters in the "Document Language" pull down menu.
Select PDF output style that determines the type of PDF to output. Select one of the following options in the "Output" pull down menu:
- Searchable Image - ensures that text is searchable and selectable. This option keeps the original image, deskews it as needed, and places an invisible text layer over it. The selection for "downsample images" in this same dialog box determines whether the image is downsampled and to what extent.
- Searchable Image (Exact) - ensures that text is searchable and selectable. This option keeps the original image and places an invisible text layer over it. Recommended for cases requiring maximum fidelity to the original image.
- Editable Text & Images - synthesizes a new custom font that closely approximates the original, and preserves the page background using a low-resolution copy.
The "Downsample To" pull down menu allows to decrease the number of pixels in color, grayscale, and monochrome images after OCR is complete. Choose the degree of downsampling to apply. Higher-numbered options do less downsampling, producing higher-resolution PDFs.
Click "OK" to save changes and close the dialog.
.PNG)
Step 5 - Start Processing
Click "Recognize Text" button to starting recognizing text.
.PNG)
Inspecting the Results
The text recognition creates a layer of text in the PDF that can be searched, or copied and pasted into a new document.
.PNG)
When you run OCR on a scanned output, the Acrobat® analyzes bitmaps of text and substitutes words and characters for those bitmap areas. If the ideal substitution is uncertain, software marks the word as suspect. Suspects appear in the PDF as the original bitmap of the word, but the text is included on an invisible layer behind the bitmap of the word. This method makes the word searchable even though it is displayed as a bitmap.
Note that OCR operation does not guarantee that all text in a PDF document would be recognized correctly. The text recognition accuracy mainly depends on the scanned document quality, but there are many other facts that can affect the result.
Example 1: 100% Recognition Accuracy
The first example shows the correct text recognition. The original PDF file has no selectable or searchable text. The text can be selected, and copy/pasted into the resulting PDF. The selected text has been copy/pasted into the text editor to show the text recognition results. All characters have been correctly identified in the following example:
.PNG)
Example 2: Recognition with Few Errors
The second example illustrates the case when some characters are not recognized correctly. Although the text is searchable, it doesn't match the original image. There are few errors on the page: the "security" is incorrectly recognized as "securitv", the last digit 9 is recognized as 2: "123-456-789" instead of "123-456-782":
.PNG)
Example 3: Low Accuracy
The third example illustrates the case with a large number of recognition errors. Although the text is still searchable, it is useless for any practical purpose. The word "CONFIDENTIAL" is recognized as "C9NFJDtNTJAL":
.PNG)
The Adobe® Acrobat® allows to correct "suspect" words if the ideal substitution is uncertain.
Optionally, select "Recognize Text > Correct Recognized Text" in the "Enhance Scans" toolbar. The Acrobat® identifies suspected text errors and displays the image and text side by side. All suspect words on the page are enclosed in boxes. Click the highlighted object or box in the document, and then correct it in the "Recognized As" box in the toolbar. Click "Accept" once the word was corrected. The next suspect is automatically highlighted. Correct mistakes as needed. Click "Accept" for each correction. Click "Close" in the second-level toolbar when the task is complete.
.PNG)
Step 7 - Save Searchable PDF Document
Do not forget to save the processed PDF document. Click "File > Save As..." in the main menu.
.PNG)
Click here for a list of all step-by-step tutorials available.