Computing Text Similarity
- Introduction
- This article explains the text similarity algorithm that is used in "Find and Delete Duplicate Pages" operation available in AutoSplit plug-in for Adobe Acrobat.
- Modified Cosine Metric
- The "Find and Delete Duplicate Pages" operation is using a modified cosine similarity metric to compare page text. The cosine similarity metric is widely used to calculate how similar are the two pages or documents based on their text content. With cosine similarity, all words on each page are enumerated and their frequencies are calculated. Next, two pages are compared by computing an "angle" between two pages. The more words two pages have in common, the more similar they are. The cosine similarity metric ranges from 0 to 1 (0 to 100%). The value of 1 is indicating that two pages are identical. However, the original cosine similarity may return 1 (100%) for two pages with a different number of words. For example, if a first page contains just one word - {Invoice}, and the second page contains 3 words { Invoice Invoice Invoice}, then the cosine similarity metric will consider these pages identical. This is a desirable behavior for the information retrieval applications, but it is not suitable for the detecting page duplicates. This is why the "Find and Delete Duplicate Pages" is using a modified version of the cosine similarity. It will only consider two pages identical if the frequencies of the words are identical on both pages. This metric computes a much lower similarity value for the above example and will not consider such pages identical. Here is the equation for the modified cosine metric:
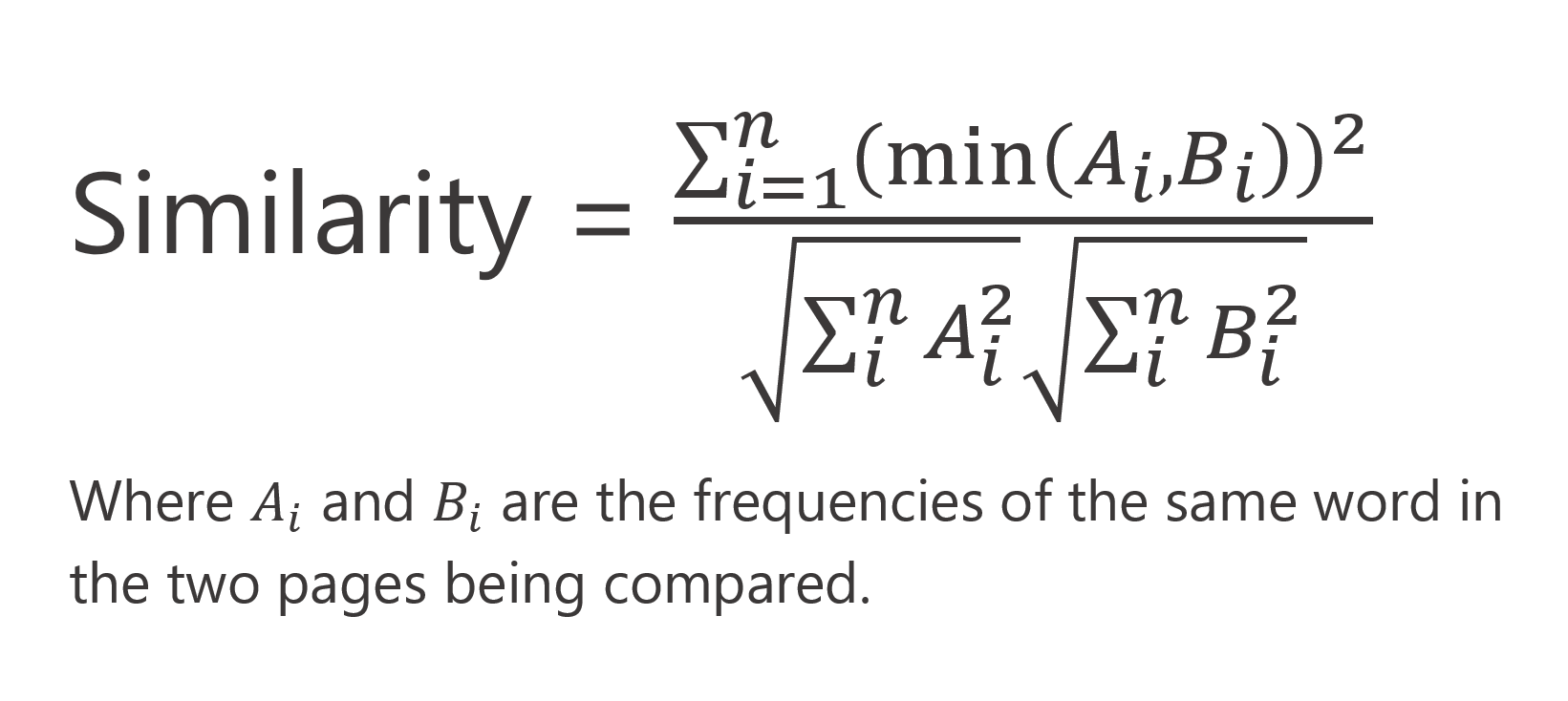
- Text Order and PDF Format
- The cosine similarity metric does not take into account the order of the words. This is an important and necessary condition, because PDF documents (unlike regular text documents), do not require words to appear in any particular order. PDF format is actually a graphic format, where each letter or group of letters is placed at specific page location (x,y). The order of the words does not really matter, because it is possible to shuffle all words or even letters in any arbitrary order without affecting the visual appearance of the page. This fact is important to remember when comparing pages that may have been produced by different applications or at different conditions. For example, if two pages where produced by scanning and OCR-ing paper documents at two different facilities, then the order of the words of each page may be different. This is why PDF page similarity is computed without taking into account the order of the text.