
Find and Delete Duplicate PDF Pages
AutoSplit plug-in for Adobe® Acrobat®
Introduction
This tutorial shows how to find and optionally delete similar or duplicate pages within the same PDF document using the AutoSplit™ plug-in for the Adobe® Acrobat®. This operation detects identical or similar pages and presents them to the user for a review. The user can review the results and select/unselect individual pages from the list of duplicates for a possible deletion or extraction. Detection algorithm is fast and can find duplicate pages in large PDF documents in matter of seconds.
You can perform the following operations:
- Find duplicate and near-duplicate pages
- Bookmark duplicate pages
- Extract duplicate pages into a separate PDF document
- Delete duplicate pages from the document
- Save page similarity report
Visual Appearance vs Text Content
It is important to distinguish between two approaches for identifying duplicate PDF pages. The appropriate method depends on the specific application. Pages can be compared either based on their visual appearance or their underlying text content (if present). Visual comparison treats two pages as duplicates only if they look the same, including layout, formatting, and graphical elements. In contrast, textual comparison considers pages identical if they contain the same text, regardless of how that text is presented visually. In most cases, visual comparison is the preferred approach.

The plug-in provides two different methods for detecting duplicate or near-duplicate pages:
METHOD 1: Compare Visual Appearance of the Pages
This method compares pages "as images" and detects pages that look exactly the same or similar. Sensitivity of the algorithm can be adjusted to find pages that have small differences and look similar. This detection method cannot detect identical pages that have been rotated. This method does not compare any invisible text that may be present on the page. It can be used on both regular and scanned PDF documents.
Jump to the instructions.
METHOD 2: Compare Page Text Only
Use this method to compare page text regardless of its visual appearance. It computes page similarity based on text content only and completely ignores text appearance, layout, images and graphics that might be present on the page. It is the best method to detect duplicates in most document types.
Jump to the instructions.
Using Scanned Paper Documents
Quite often this operation is used to find duplicate pages in the scanned paper documents. If you want to use text-based method, then it is necessary to make sure the PDF document has searchable text. It maybe more practical to use image-based detection method on this type of PDF documents since it does not require any searchable text.
The scanned documents need to be processed with Recognize Text tool prior to using them for any text-based processing. The OCR is a process of recognizing text in scanned documents and making them searchable. It is essential to understand that text recognition in scanned documents is prone to errors and it is rarely 100% accurate. The number of errors depends on scanning resolution and original document quality. In most common cases, a scanned page may contain between 1 to 10 recognition errors where certain letters are incorrectly identified. For example, depending on the font, the lowercase letter l can look exactly like the numeral 1 . The uppercase letter O is often misidentified as the numeral 0, or uppercase letter S as the numeral 5 and etc. Since many alphanumeric symbols share similar, or identical, physical characteristics, differentiation often poses a challenge. This is why a similarity-based comparison comes useful to detect small differences between pages that are produced by the text recognition process. Low quality scanned documents may contain a large number of errors making them unusable for any reliable text-based comparison. See the following tutorial on how to recognize text in scanned documents and asses their suitability for the text-based processing. .
Prerequisites
You need a copy of the Adobe® Acrobat® along with the AutoSplit™ plug-in installed on your computer in order to use this tutorial. You can download trial versions of both the Adobe® Acrobat® and the AutoSplit™ plug-in.
Step-by-Step Tutorial
Contents
Method 1 - Comparing Visual Appearance Only ↑overview
This method compares pages "as images" and detects pages that look exactly the same or similar. This method does not compare any invisible text that may be present on the page. This method can be used on both regular and scanned PDF documents.
Step 1 - Open a PDF File
Start the Adobe® Acrobat® application and open a PDF file using File > Open... menu.
Step 2 - Open the "Find Duplicate Pages" Dialog
Select Plugins > Split Documents > Find and Delete Duplicate Pages... to open the "Find Duplicate Pages" dialog. Please see the link below for details how to find Plugins menu in different versions of Adobe Acrobat.
[⚡ How to locate Plugins menu in Adobe® Acrobat® ⚡]
Step 3 - Specify Settings
Check the "Compare visual appearance of the pages" option.
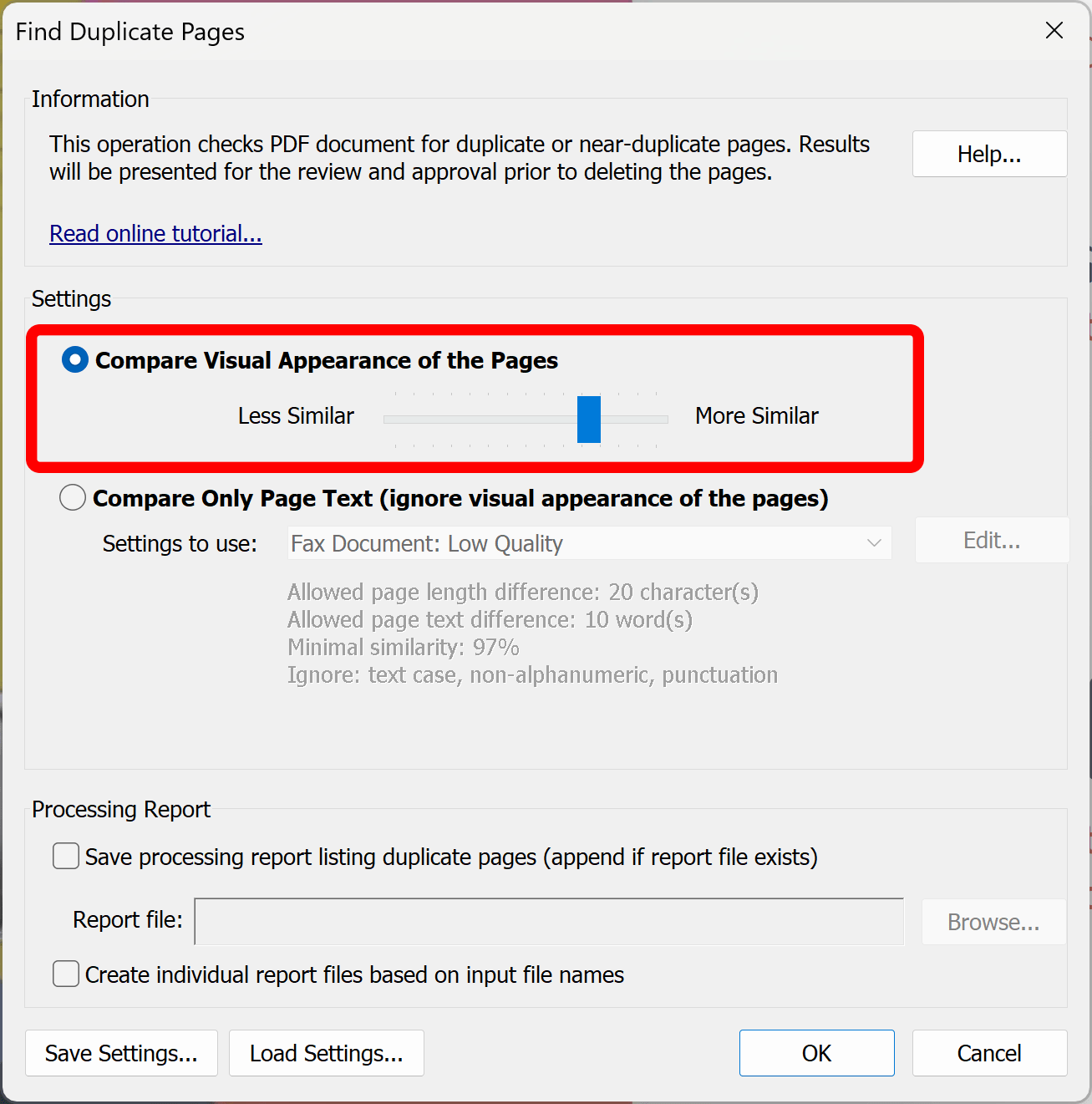
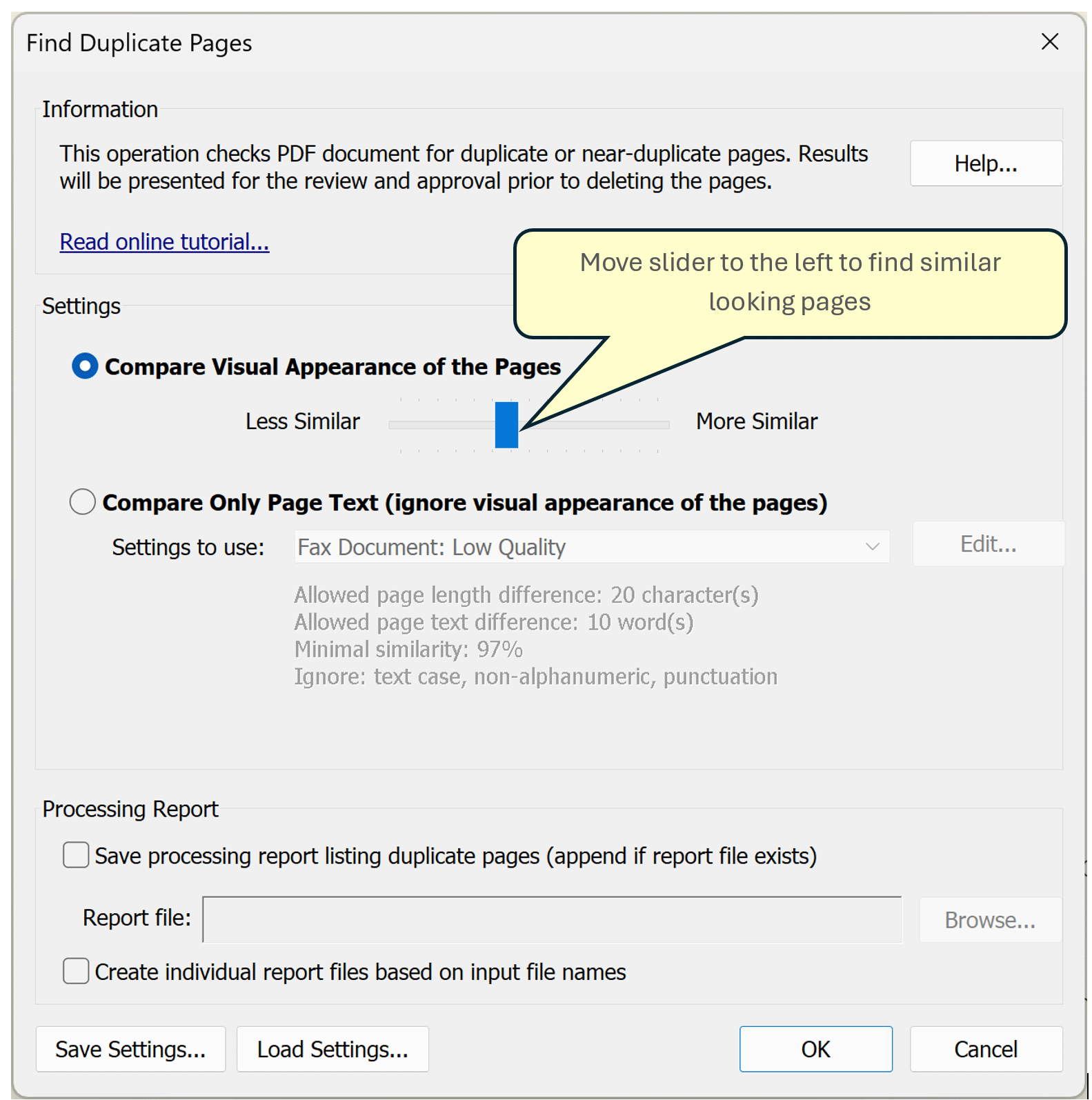
Adjust similarity slider (Less Similar -- More Similar) to find either exact matches or pages that may look similar but not exactly the same. You will need to experiment with different position of the slider depending on the PDF document and desired results. The processing runs a bit faster when looking for less similar images.
Click "OK" to start searching for duplicate pages.
Step 4 - Inspect Duplicate Pages
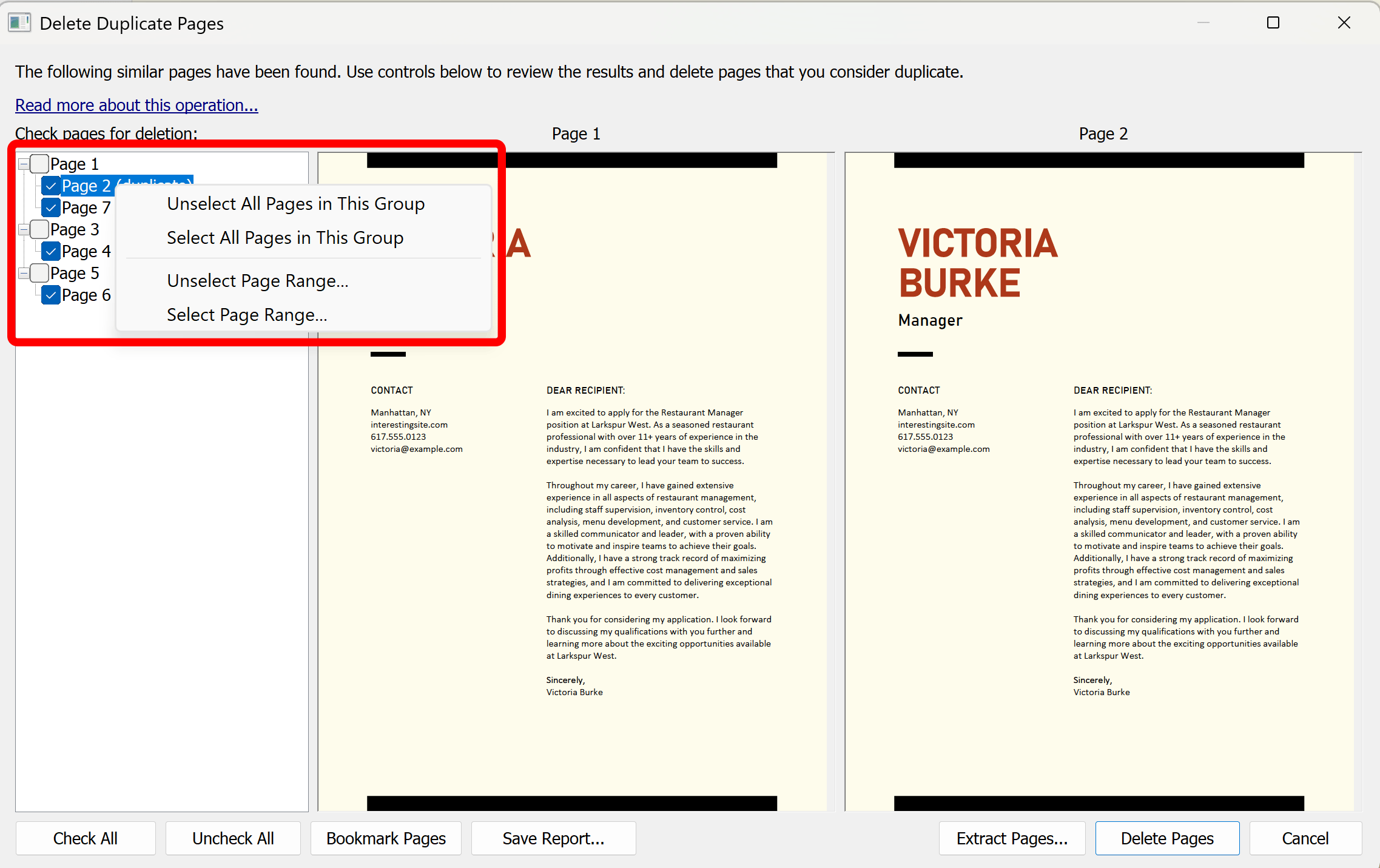
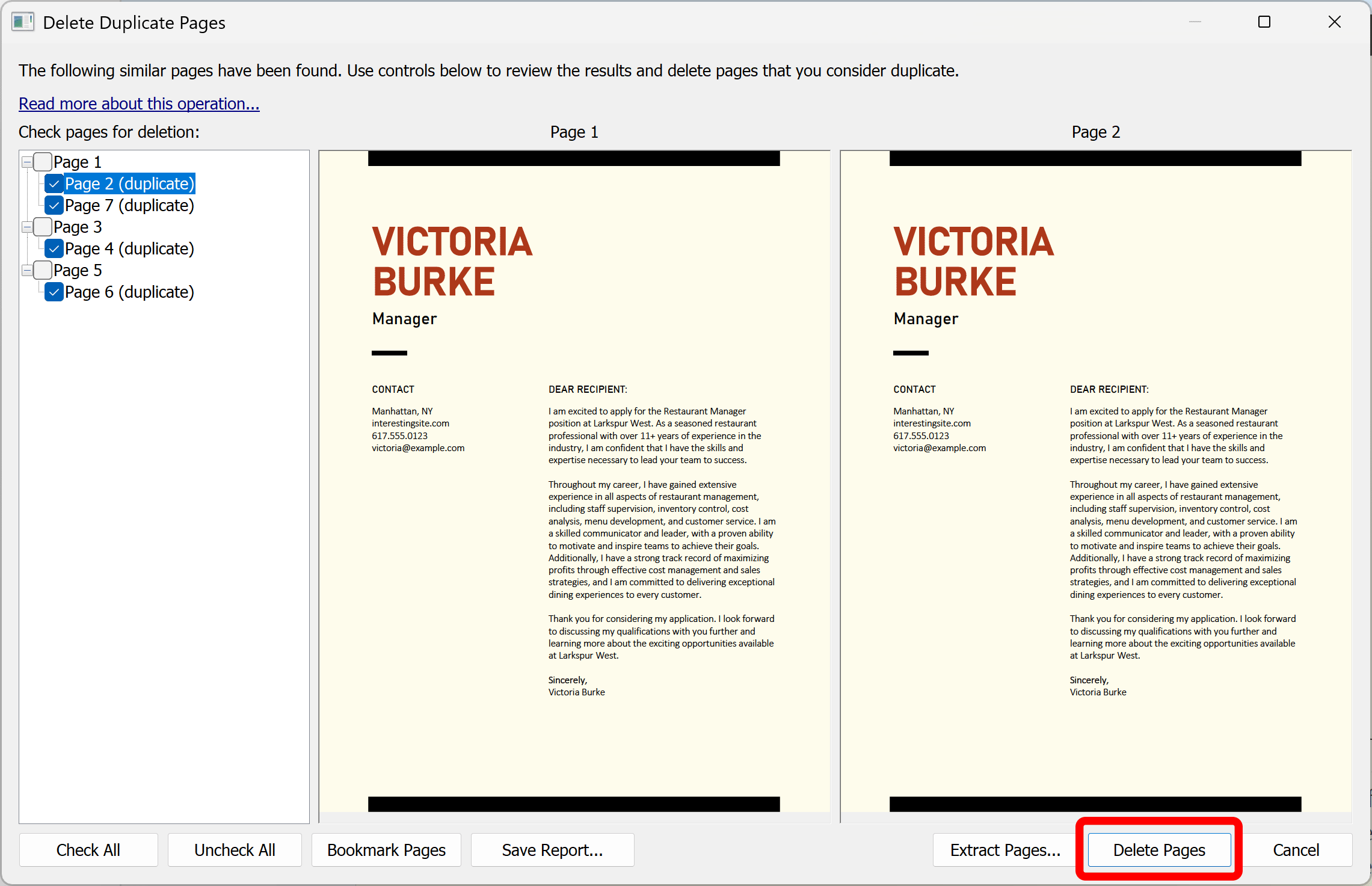
The "Delete Duplicate Pages" dialog shows a list of duplicate or near-duplicate pages. Click on a page record to display the corresponding page in the side-by-side view. Examine pages and select/unselect pages for a possible deletion.

Select/Unselect Duplicates
Inspect the duplicate pages by clicking on the pages in the list. Use a checkbox in front of each page to select/unselect this page from the duplicate page set. Right-click on the pages to access the popup menu that allows check/uncheck all pages in the group and check/uncheck page ranges.
Finding Similar Pages
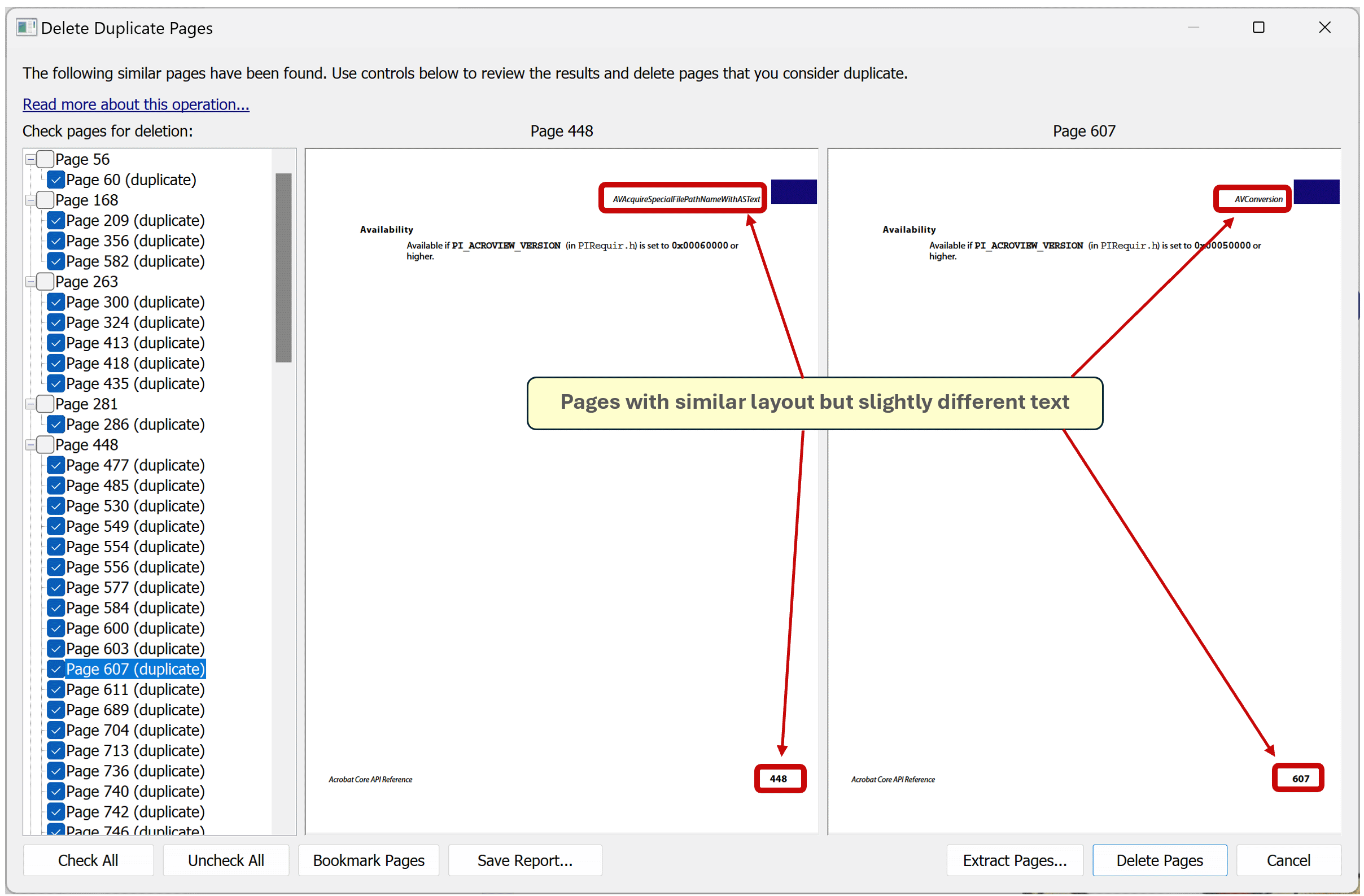
You can use this method to find pages that look similar or have similar layout. Move sensitivity slider to the left (Less Similar) and run processing multiple times with different setting until you get the desired results.
Here is an example of pages with similar layout but with a slightly different text.
Optionally, click "Save Report..." button to output a page similarity report in HTML format. Click "Bookmark Pages" button to create bookmarks in the current document for the selected duplicate pages.
If pages are visually identical, then the software detects them as duplicates:
.PNG)
These two pages are considered different due to the "Approved" stamp on the one of the pages:
.PNG)
These two pages are consider identical by this method:
.PNG)
Unlike the text-based comparison method, if the color or style of the text is different, then the pages are not considered identical:
.PNG)
Step 5 - Delete Duplicate Pages
Click "Delete Pages" in the "Delete Duplicate Pages" dialog to proceed.
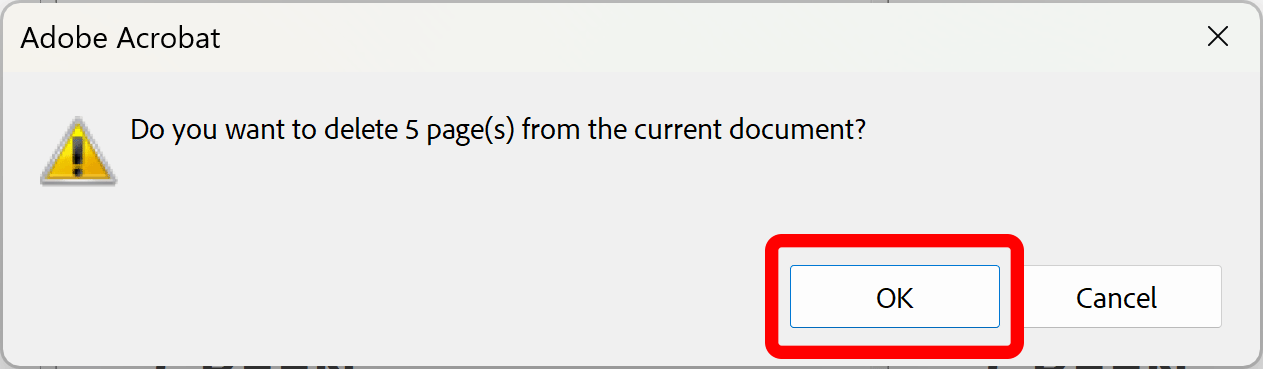
Click "OK" button to delete pages from the current PDF documents. Pages will be permanently removed.
Comparing Multiple PDF Documents
This operation can be used to find and remove duplicate pages from the multiple PDF documents. The approach is to combine one or more documents into a single PDF file and run “Find and Delete Duplicate Pages” operation on the resulting file. This will essentially produce a single document without any duplicates. Optionally, it is possible to extract all detected duplicate pages into a separate PDF document.
Step 1 - Combine Multiple PDF Documents ↑overview
Start the Adobe® Acrobat® application and select "Tools" from the menu. Select "Combine Files" icon from the Tools list.
.PNG)
Click "Add Files..." in the "Combine Files" menu and select PDF files to merge for comparison.
.PNG)
Click the "Combine" button in the menu to merge selected PDF files.
.PNG)
Step 2 - Find Duplicate Pages in the Merged File
Use the step-by-step instructions above (for the single document) on the merged PDF document to find and delete duplicate pages.
COMING SOON: The next version of the software will provide functionality to find duplicates in multiple PDF documents without merging files into a single document.
Method 2 - Comparing Page Text Only ↑overview
This method compares page similarity only based on text content. The visual appearance, text position, and text order are irrelevant. This method also ignores any images and graphics/drawings present on the pages. The modified cosine similarity metric is used to calculate how similar two pages are based on their text content. You can adjust sensitivity of the algorithm based on maximum allowed difference in text length, number of words and characters.
Step 1 - Open a PDF File
Start the Adobe® Acrobat® application and open a PDF file you want to process using File > Open... menu.
Step 2 - Open the "Find Duplicate Pages" Dialog
Select Plugins > Split Documents > Find and Delete Duplicate Pages... from the main Acrobat menu to open the "Find Duplicate Pages" dialog. Please see the link below for help on finding Plugins menu in different versions of Adobe Acrobat.
[⚡ How to locate Plugins menu in Adobe® Acrobat® ⚡]
Step 3 - Specify Settings
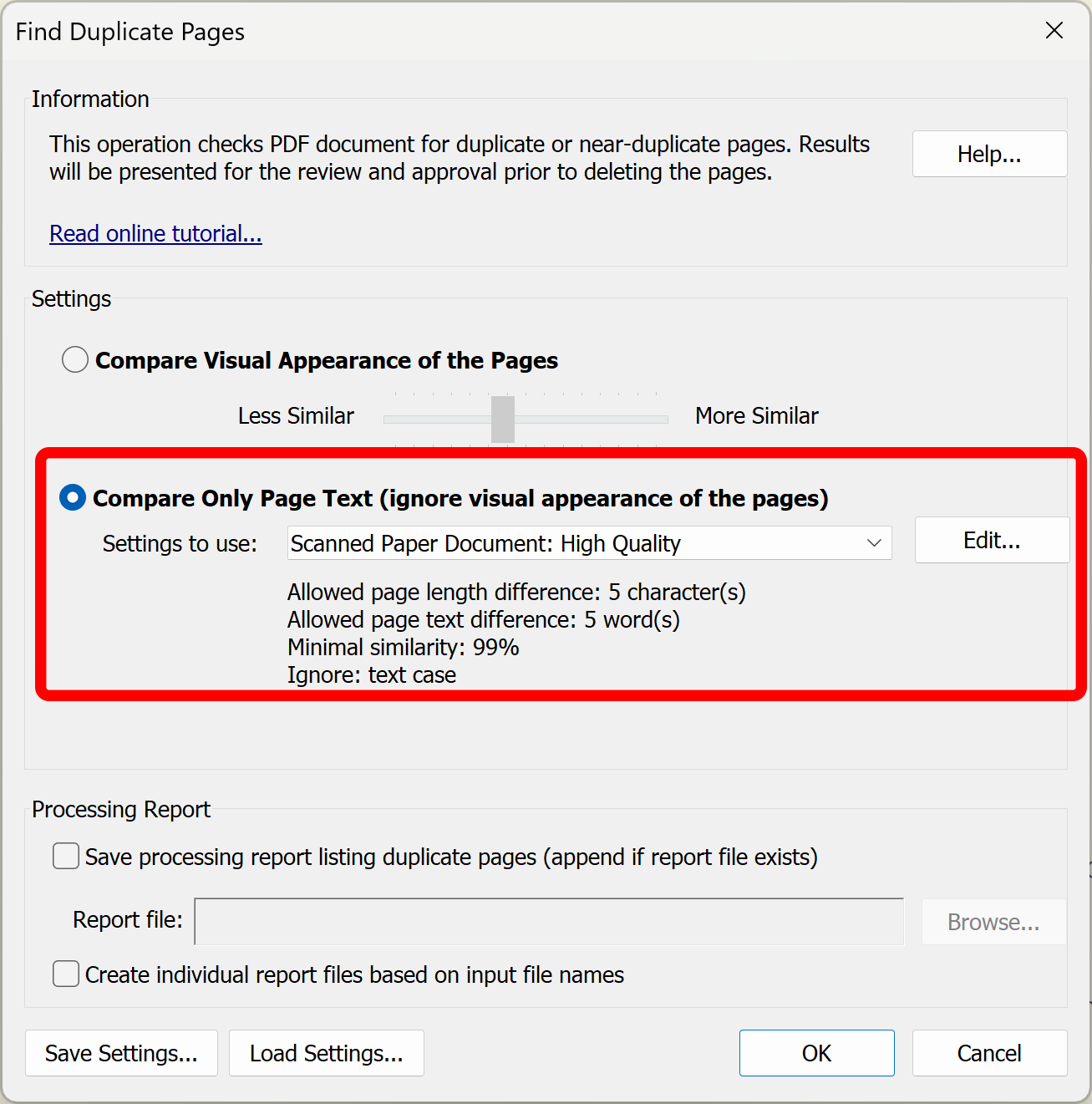
Check the "Compare only page text (ignore visual appearance of the pages)" option.
Using Predefined Settings
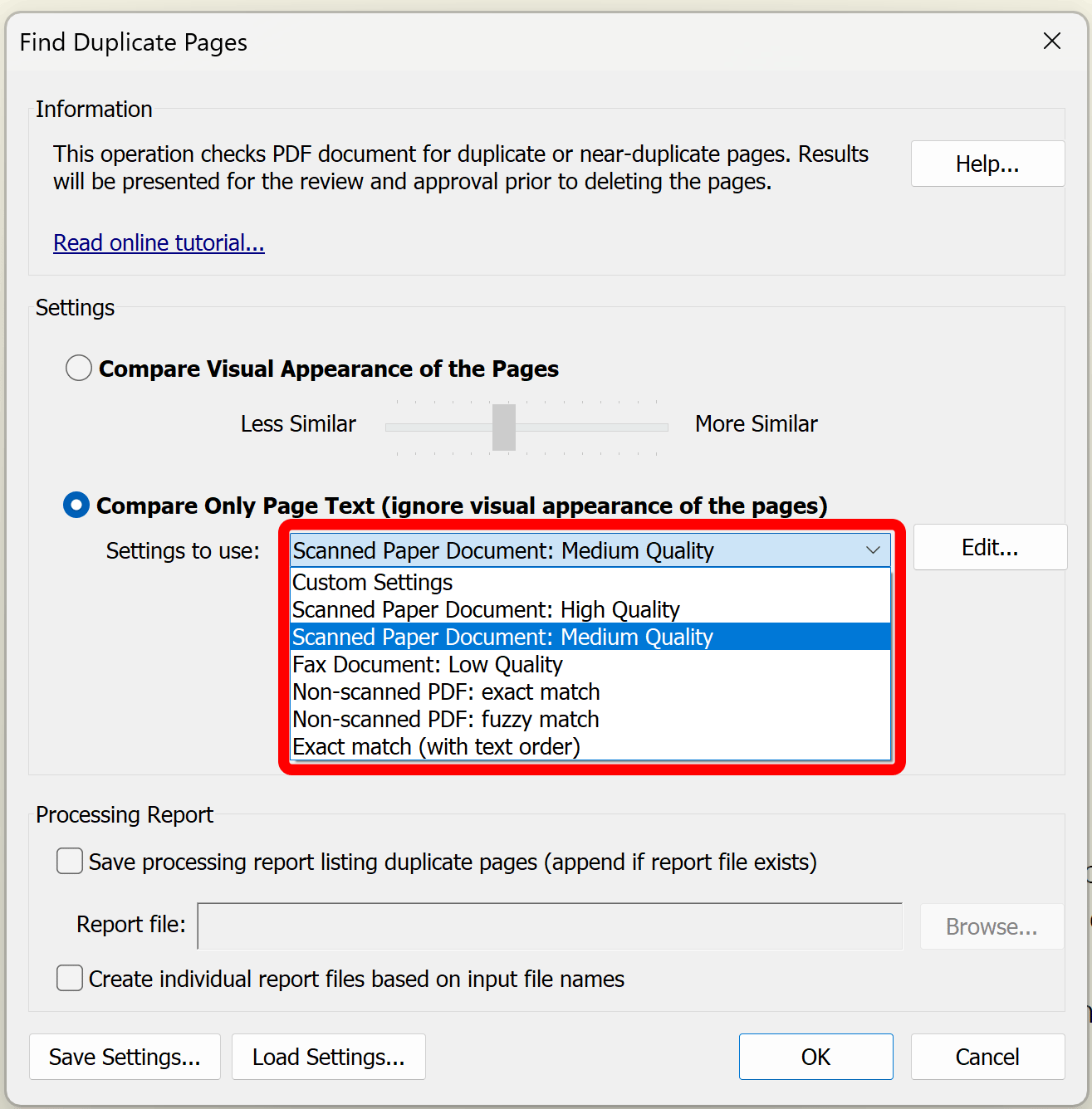
The text-based method provides a number of predefined parameters sets that are suitable for comparing different kinds of documents with a different amount of recognition errors. Each predefined set of parameters provides different conditions for similarity calculations:
- Custom Settings - all settings are specified by user
- Scanned Paper Document: High Quality
- Scanned Paper Document: Medium Quality
- Fax Document: Low Quality
- Non-scanned PDF: exact match
- Non-scanned PDF: fuzzy match
- Exact match (with text order)- this method does not use cosine similarity
Click "Edit..." button to customize page similarity settings.
The text comparison method uses 3 parameters to limit how different two "similar" pages can be. By varying these parameters, it is possible to detect pages that have a different degree of similarity.
- Minimal allowed page text similarity - this is the value of cosine similarity metric expressed as percentage (1%-100%). Specify minimum allowed page text similarity between 70% and 100%.
- Maximum allowed page length difference (in characters).
- Maximum allowed page text difference (in words).
Use these settings to experiment with processing settings when it is necessary to adjust processing algorithm for a specific document.
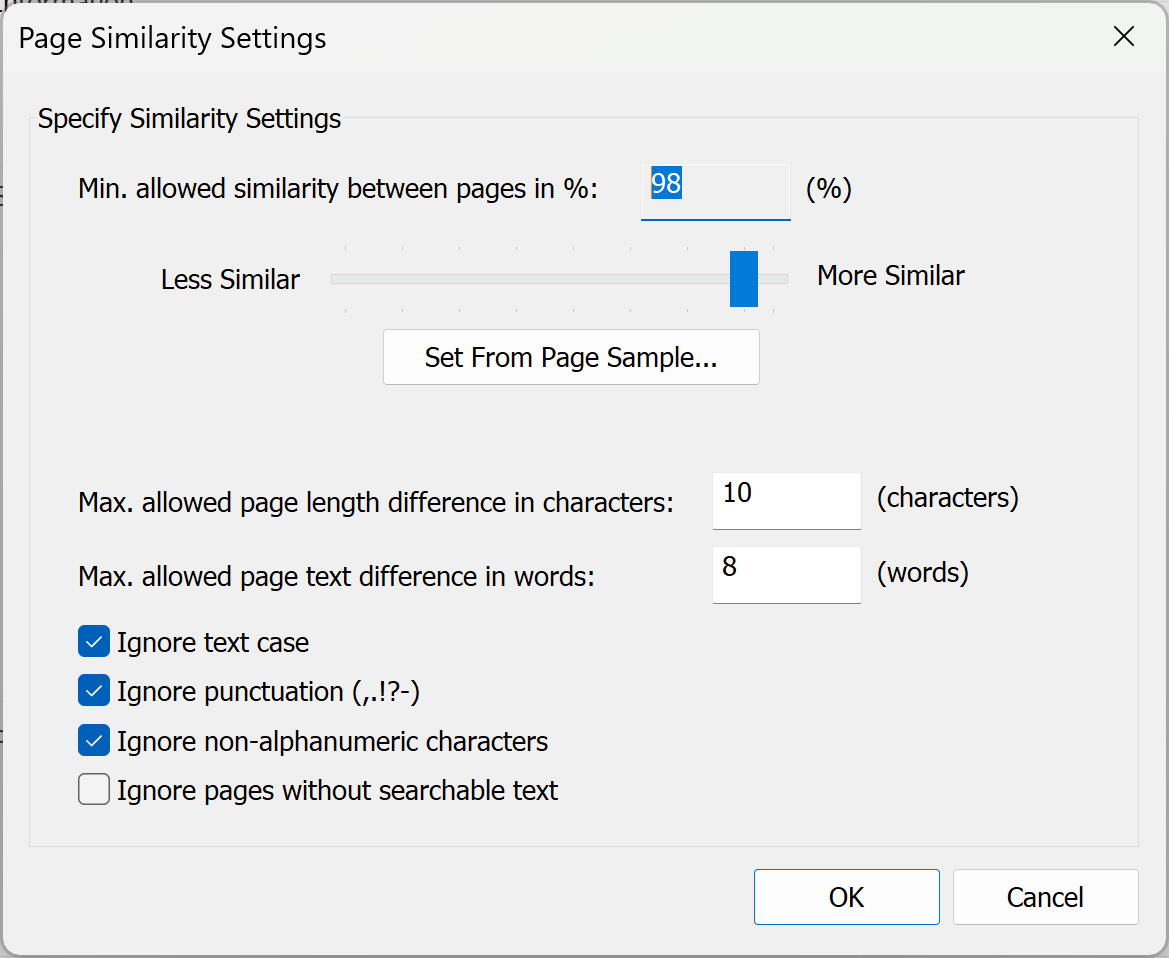
Use Sample Pages
Optionally, click "Set From Page Sample..." to specify page similarity settings based on the two sample pages:
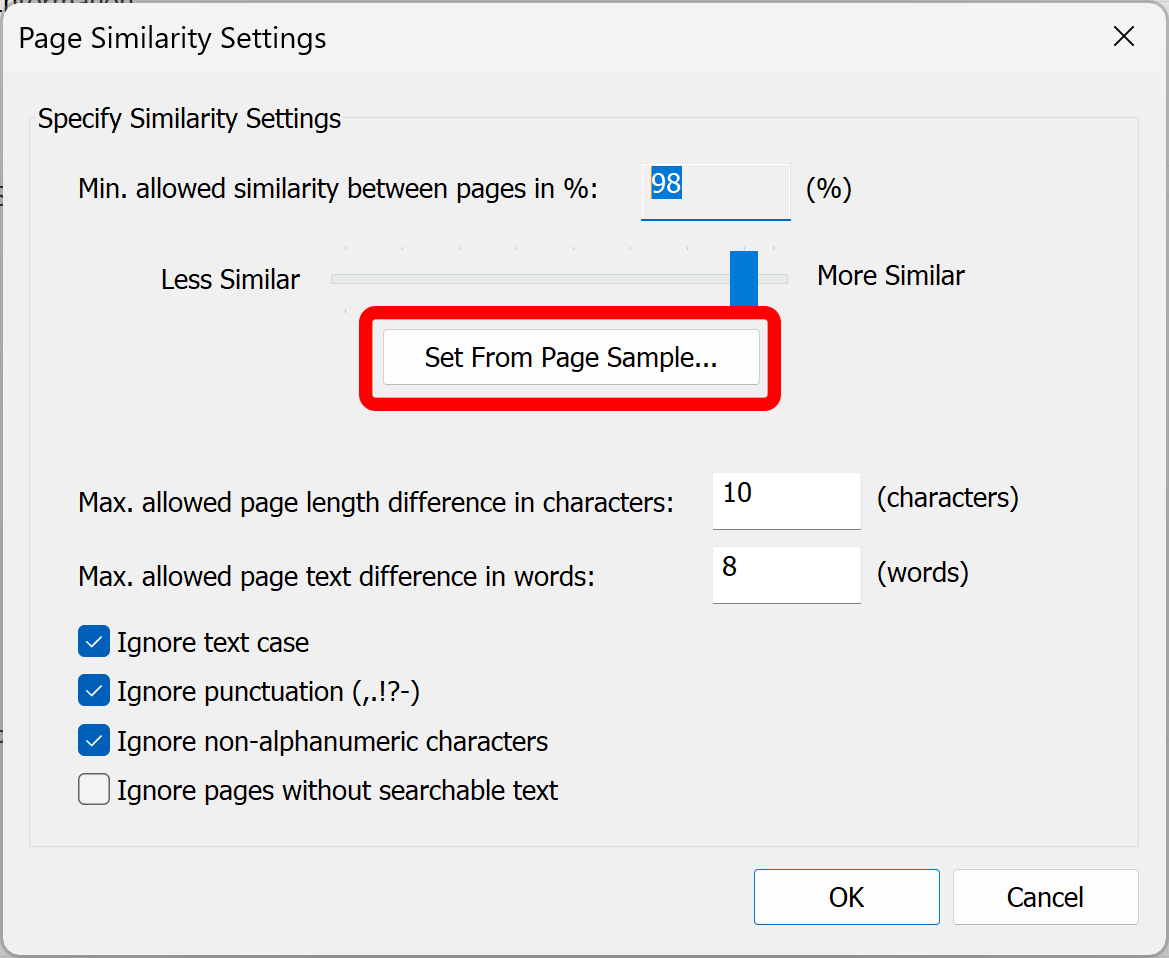
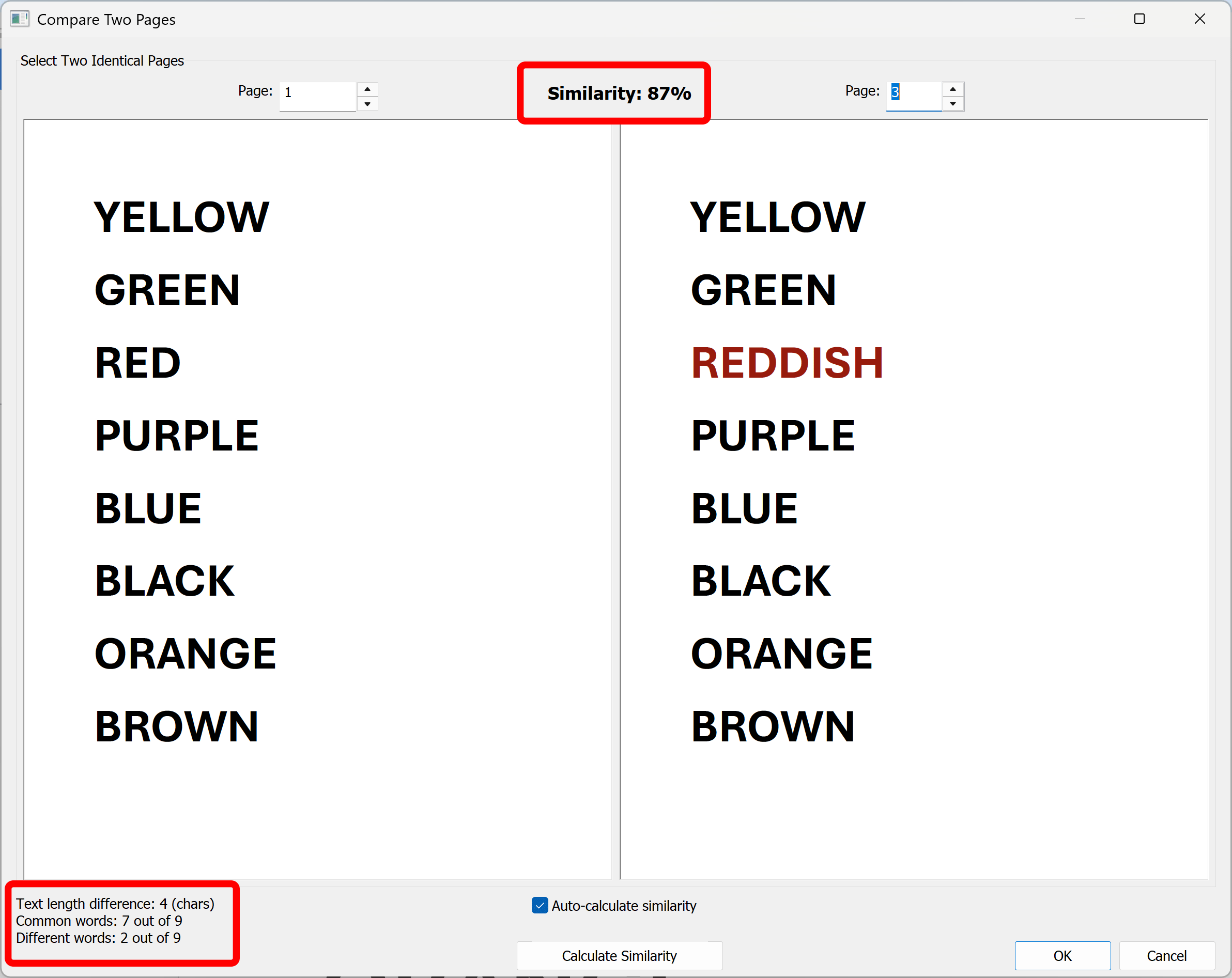
Select two pages that can be consider identical. The software will auto-calculate page similarity and the statistics will appear in the left lower corner of the dialog.
Click "OK" to save the current similarity settings.
Specify Text Filtering Options
There are several parameters that control the page content that is being analyzed by the text comparison algorithm. Use these options when comparing scanned paper documents that may contain various text recognition errors. These options exclude certain kind of characters from processing. In many cases, it may help to compute a more accurate similarity metric.
- Ignore text case - this option ignores text case while comparing text.
- Ignore punctuation (,.!?-) - this options excludes all punctuation characters from comparison.
- Ignore non-alphanumeric characters - this options ignores all characters except letters and digits.
Click "OK" to save page similarity settings.
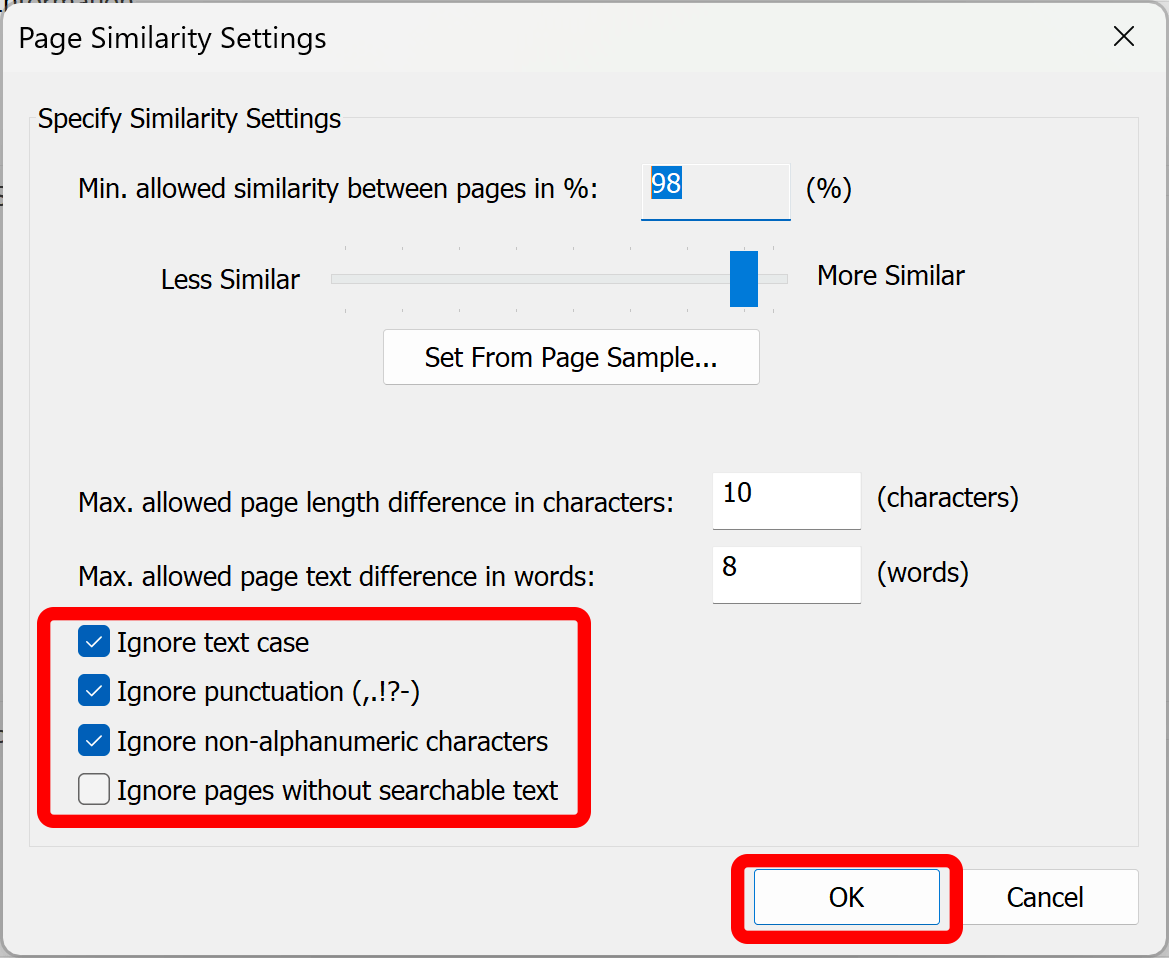
Click "OK" to start searching the current PDF document for the duplicate pages:
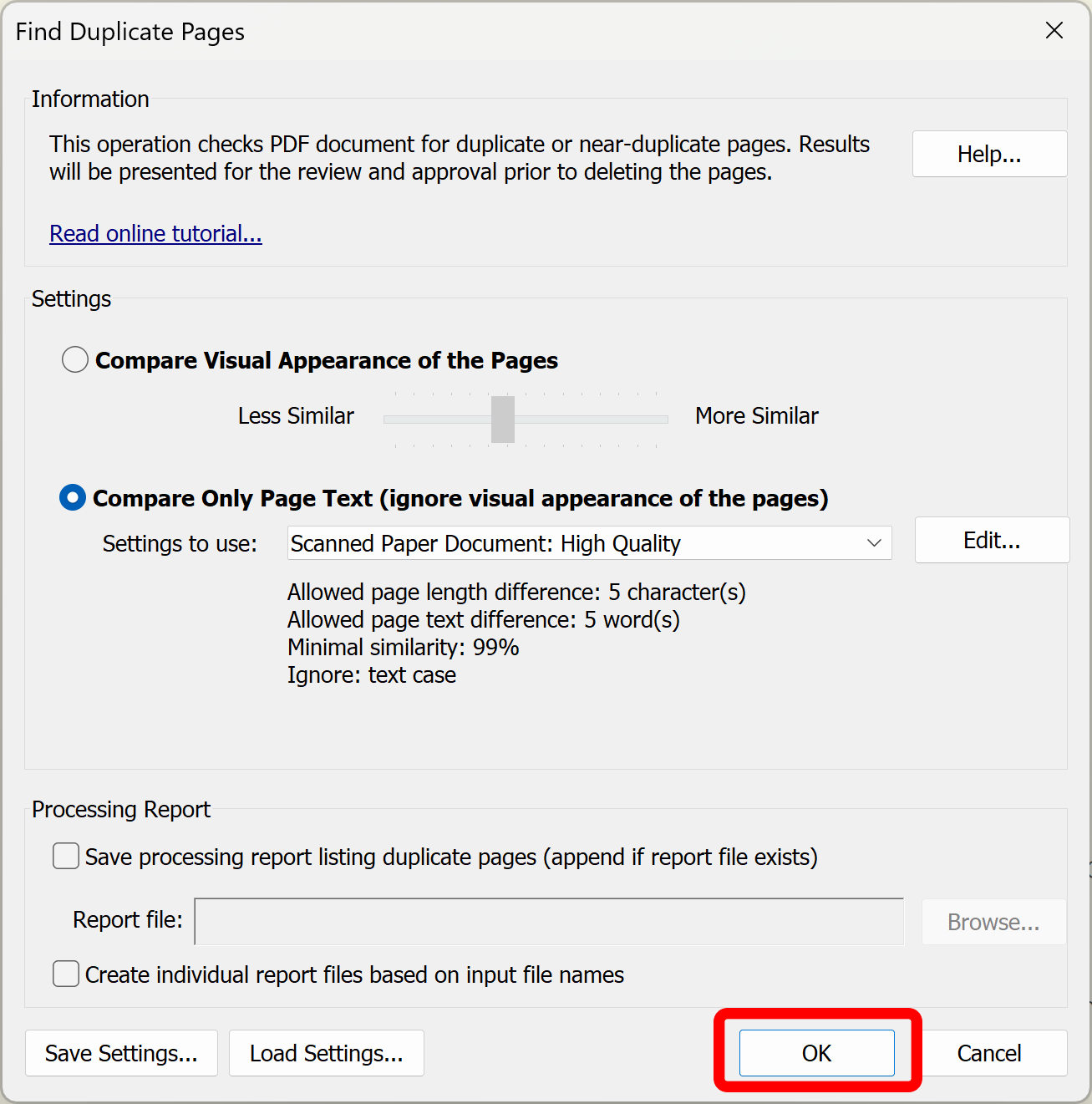
Step 4 - Inspect Duplicate Pages
The "Delete Duplicate Pages" dialog shows a list of duplicate or near-duplicate pages. Click on a page record to display a corresponding page in the viewer. Examine pages and select/unselect pages for deletion.
Optionally, click "Save Report..." to create a page similarity report in HTML format. Or click "Bookmark Pages" to create bookmarks in PDF for selected duplicate pages.
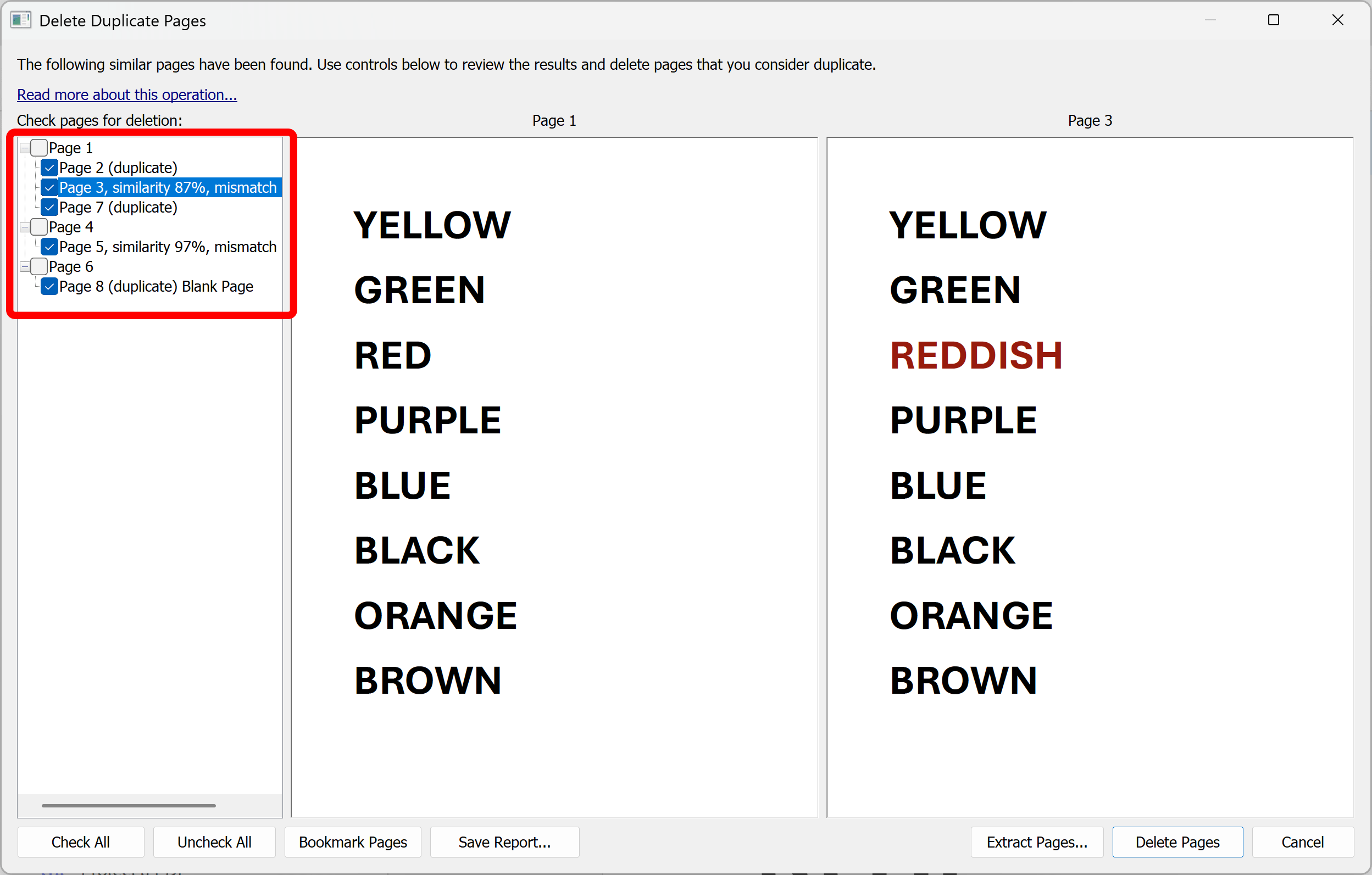
The plug-in allows to preview/compare the found duplicate or near-duplicate pages. The page similarity (in %) and the number of mismatched words is displayed for each pair of pages. Here are the examples computed for the pair of the scanned paper documents:


Note that the apperance and location of the text do not affect the results.
These two pages are considered identical despite the difference in the text color:
.PNG)
These two pages are considered identical despite the difference in the content layout:
.PNG)
These two pages are consider 94% similar despite the difference in the text order, layout and absence of the image:
.PNG)
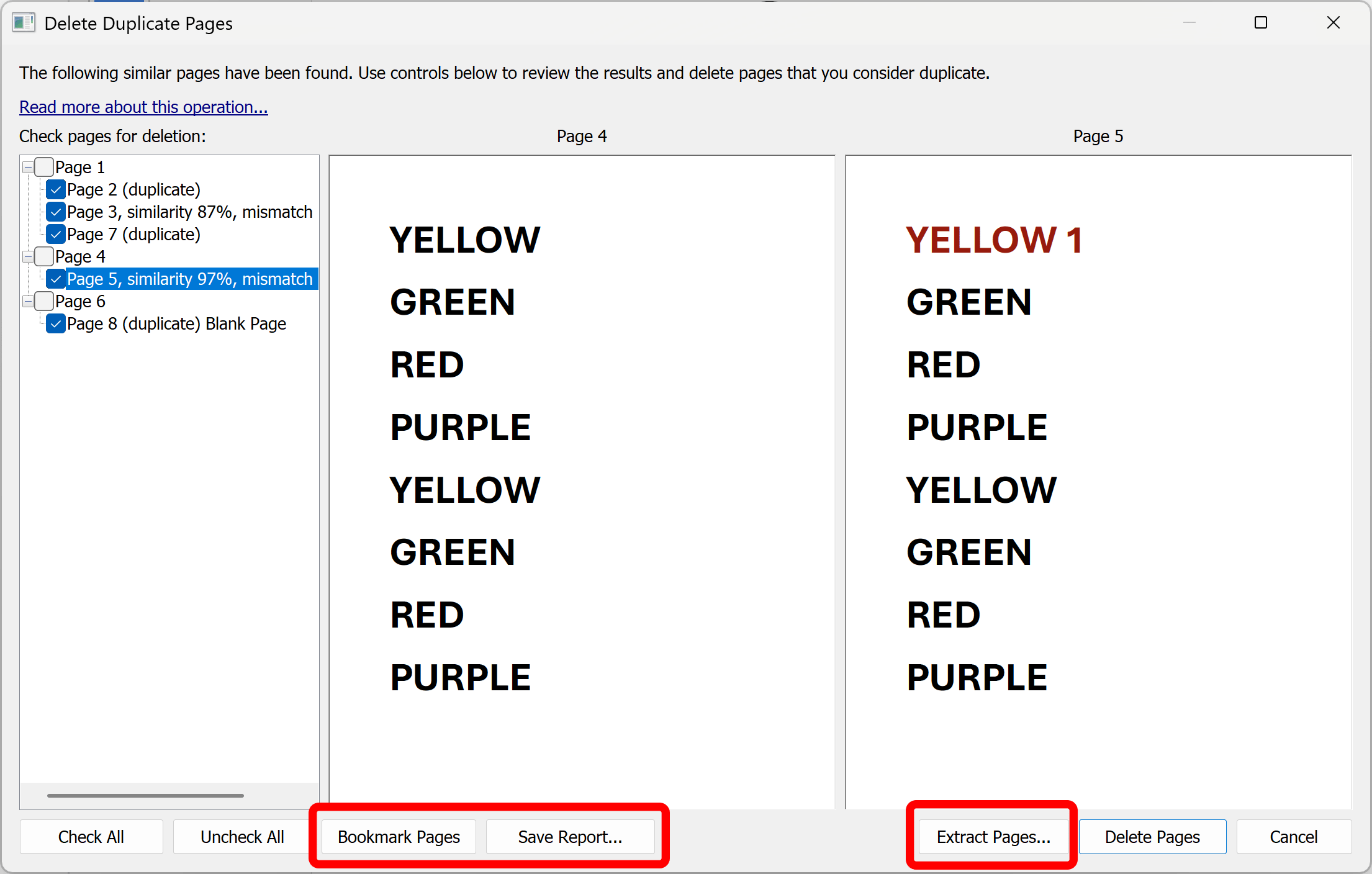
Step 5 - Extract or Bookmark Duplicate Pages
Optionally, use "Bookmark Pages" button to bookmark all checked pages. This is useful if you are not planning to delete the found duplicate pages from the document. Use checkboxes in front of the pages to select/unselect them from the processing set.
Use "Extract Pages...." button to extract all checked pages into a separate PDF document. This operation will not remove pages from the current document.
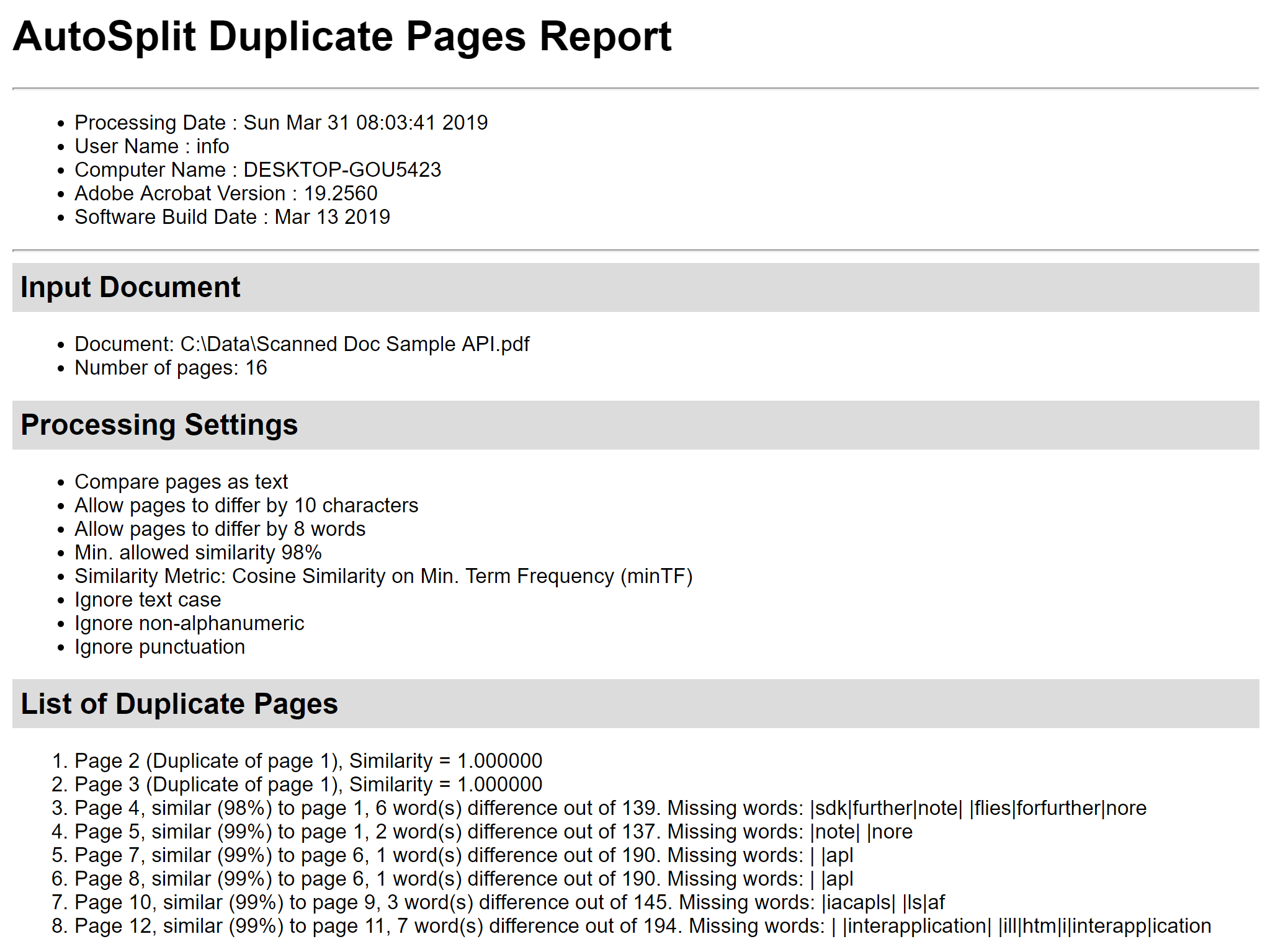
Use "Save Report..." button to save page similarity computation report into HTML file. It contains page similarity details, shows differences between pages and lists missing words. It can be very useful for the in-depth analysis.
Step 6 - Delete Duplicate Pages
Use checkboxes in front of the pages to select/unselect pages from being deleted. Press "Delete Pages" button in the "Delete Duplicate Pages" dialog to remove all checked pages from the current PDF document:
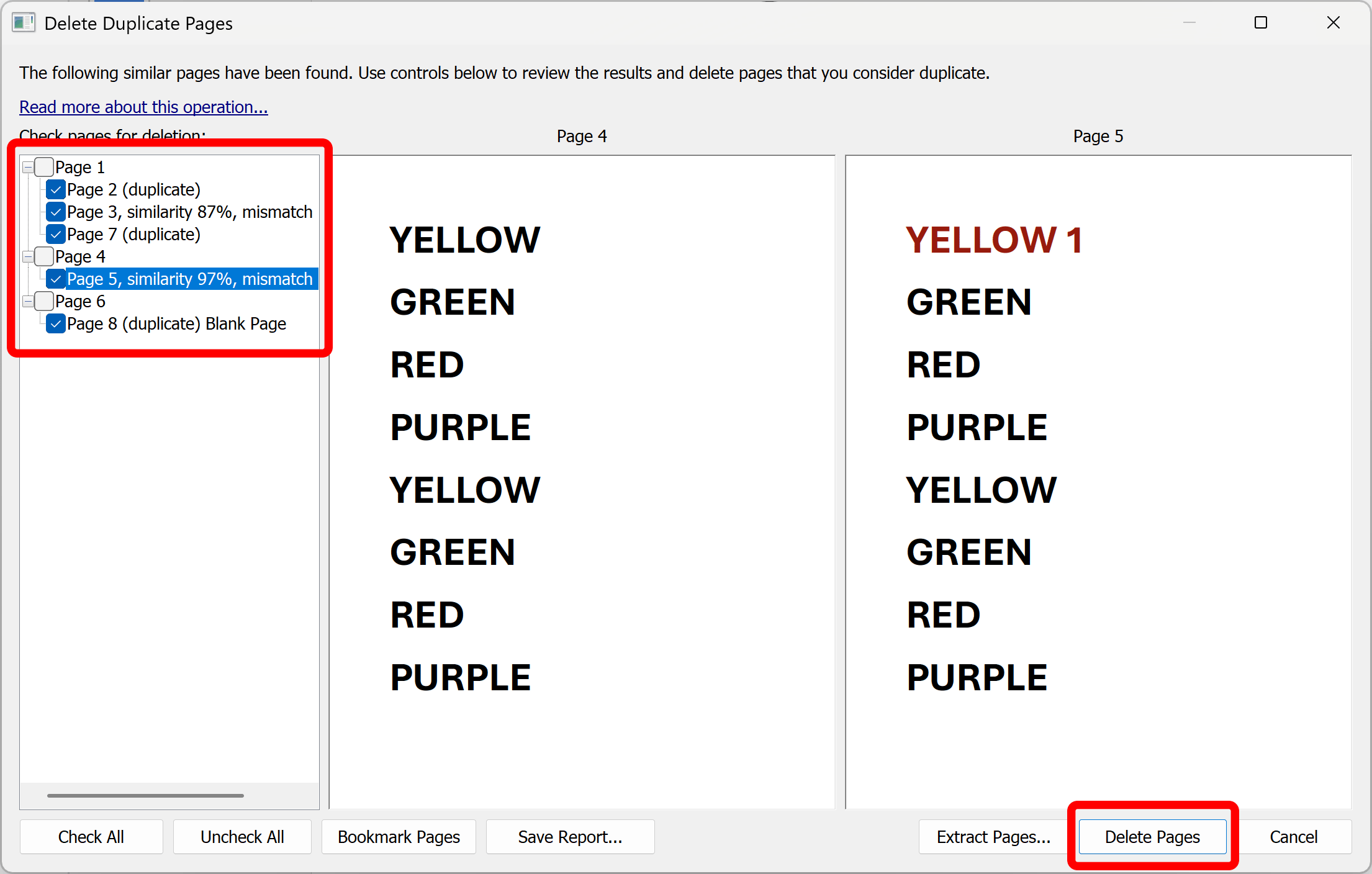
Click "OK" button to confirm. Pages will be permanently removed.
Click here for a list of all step-by-step tutorials available.