Using Scripting to Extract Document Bookmarks and Attachments
- Introduction
- Acrobat JavaScript provides access to many properties and elements of PDF documents that can be used for data extraction purposes. A document's metadata, bookmarks, file attachments, page information and text can all be accessed via custom scripting. In this tutorial, we will demonstrate how to use custom scripting to extract a document’s bookmarks and file attachments, then assign them as field values in an output *.csv spreadsheet.
- What is JavaScript?
- JavaScript is Adobe Acrobat's built-in scripting engine. Custom JavaScript scripts can be used for: data formatting; assigning field values based on a document's metadata properties; or custom processing logic. Each data field can optionally have a user-supplied script that is executed after the data value is extracted from the document. Please refer to Adobe Acrobat documentation for details on using Acrobat's JavaScript programming language.
- Prerequisites
- You need a copy of Adobe® Acrobat® along with the AutoExtract™ plug-in installed on your computer in order to use this tutorial. Both are available as trial versions.
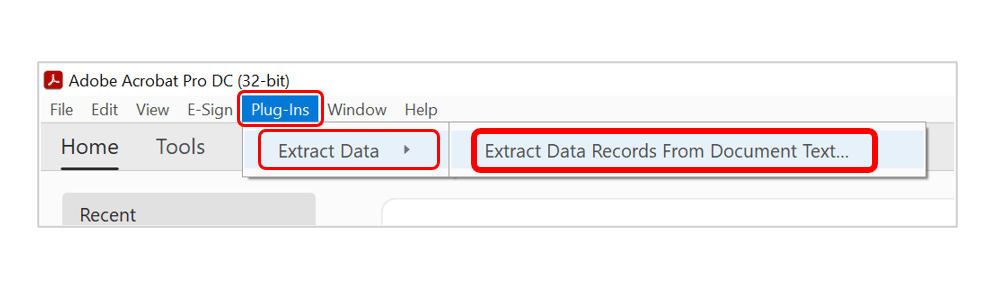
- Step 1 - Open AutoExtract
- Select "Plug-Ins > Extract Data > Extract Data Records From Document Text…" to open the "AutoExtract Plug-in" dialog.
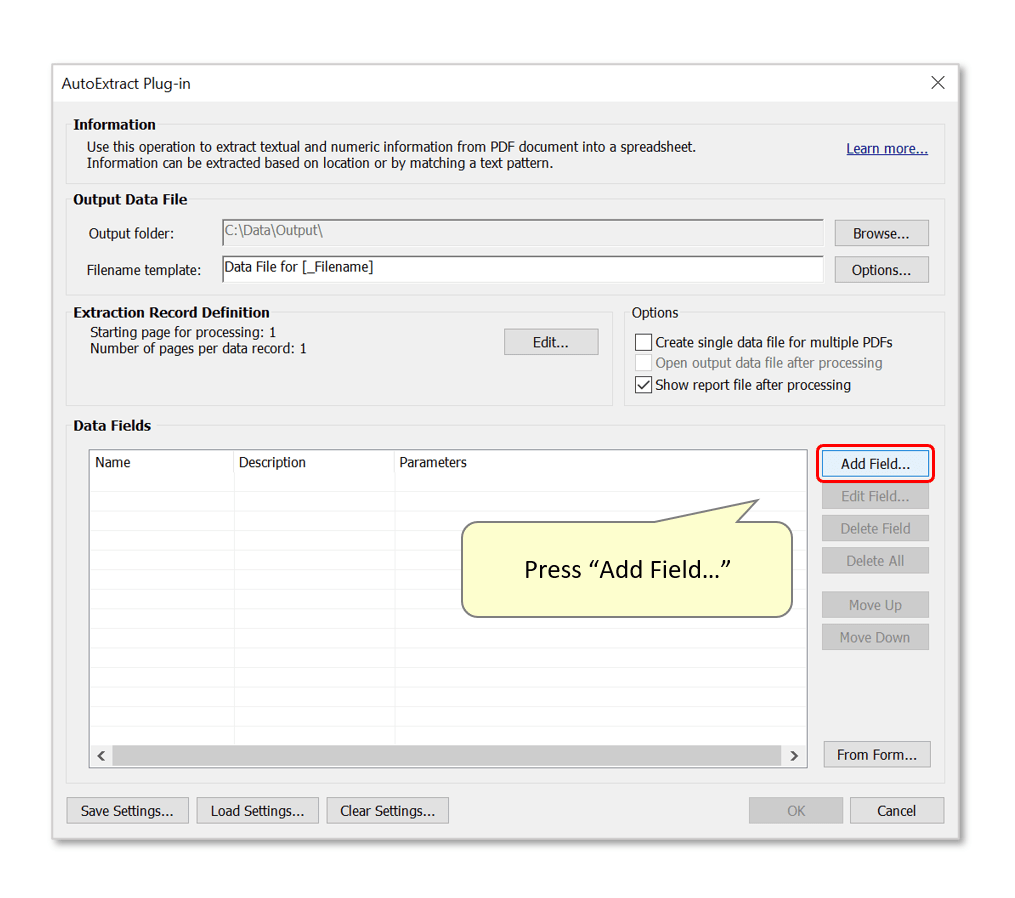
- Step 2 - Add a 'Bookmarks' Data Field
- Press the "Add Field..." button to add a field to the settings configuration.
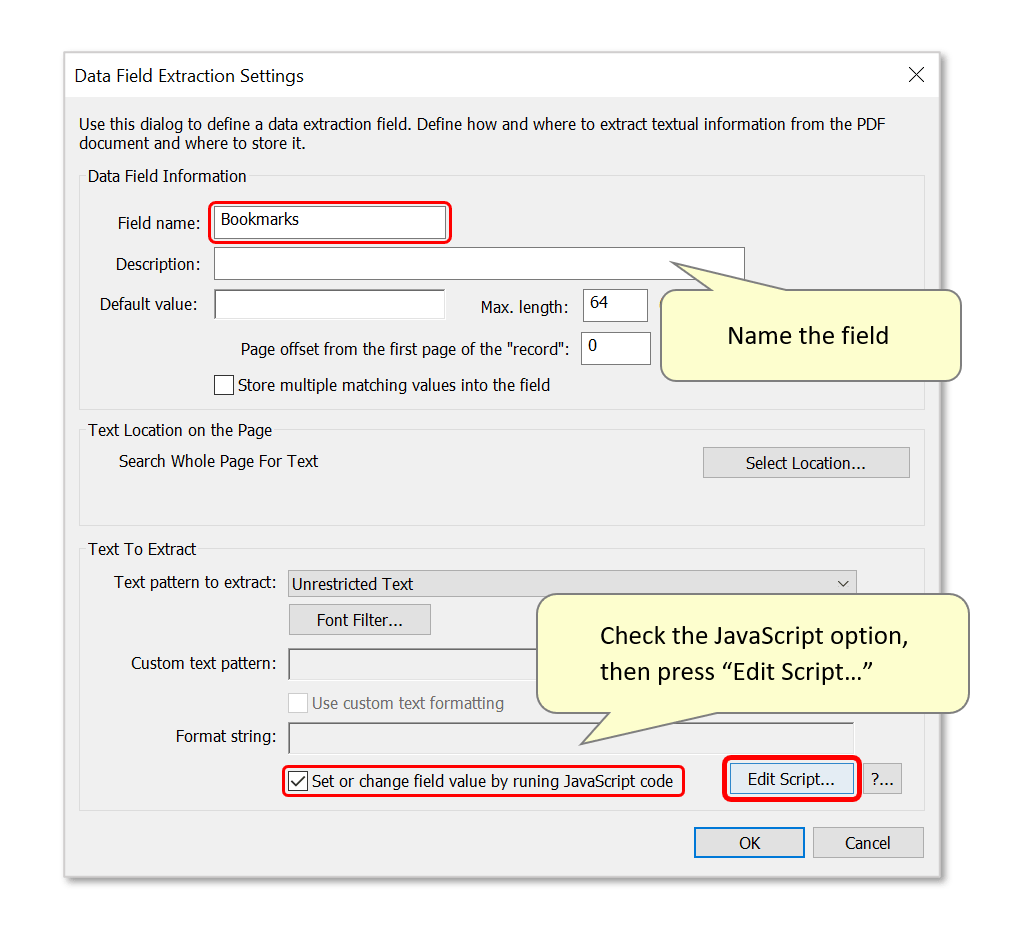
- Enter a name for the data field next to "Field name:". This will become the field header in the output spreadsheet(s).
- Next, check "Set or change field value by running JavaScript code" and press "Edit Script...".
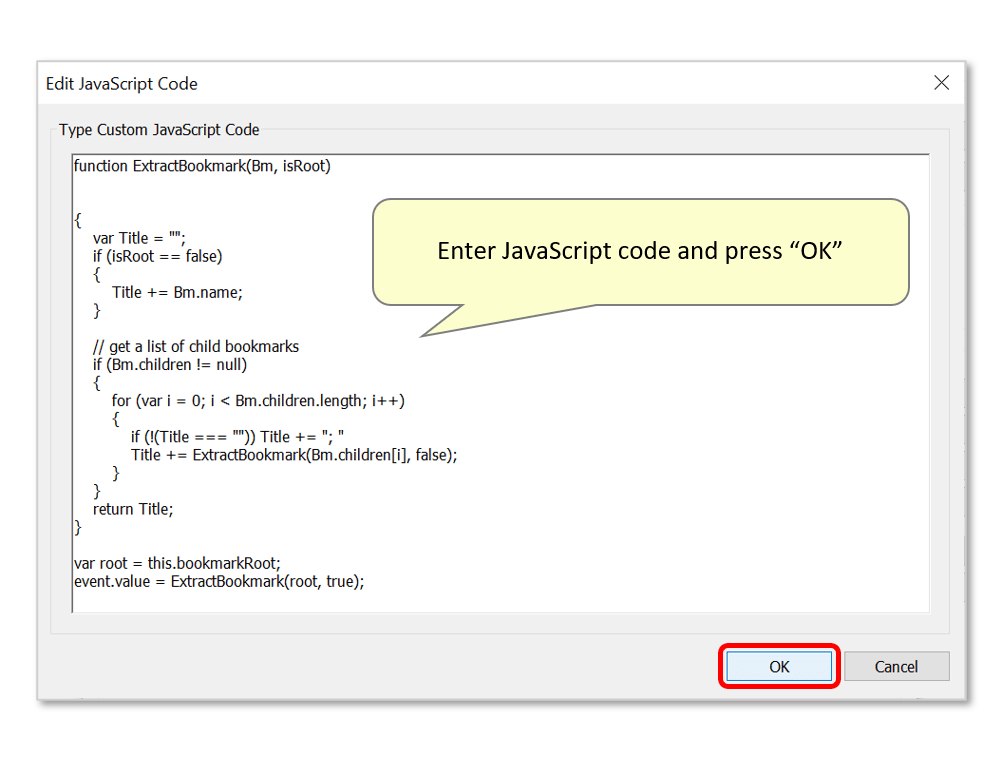
- Type the desired JavaScript code - the code used here will get a list of all bookmark titles in the PDF file (as a single text string) and assign it to the field value. Titles will be separated by a semicolon:
function ExtractBookmark(Bm, isRoot)
{
var Title = "";
if (isRoot == false)
{
Title += Bm.name;
}
// get a list of child bookmarks
if (Bm.children != null)
{
for (var i = 0; i < Bm.children.length; i++)
{
if (!(Title === "")) Title += "; "
Title += ExtractBookmark(Bm.children[i], false);
}
}
return Title;
}
var root = this.bookmarkRoot;
event.value = ExtractBookmark(root, true);
- Press "OK" to proceed.
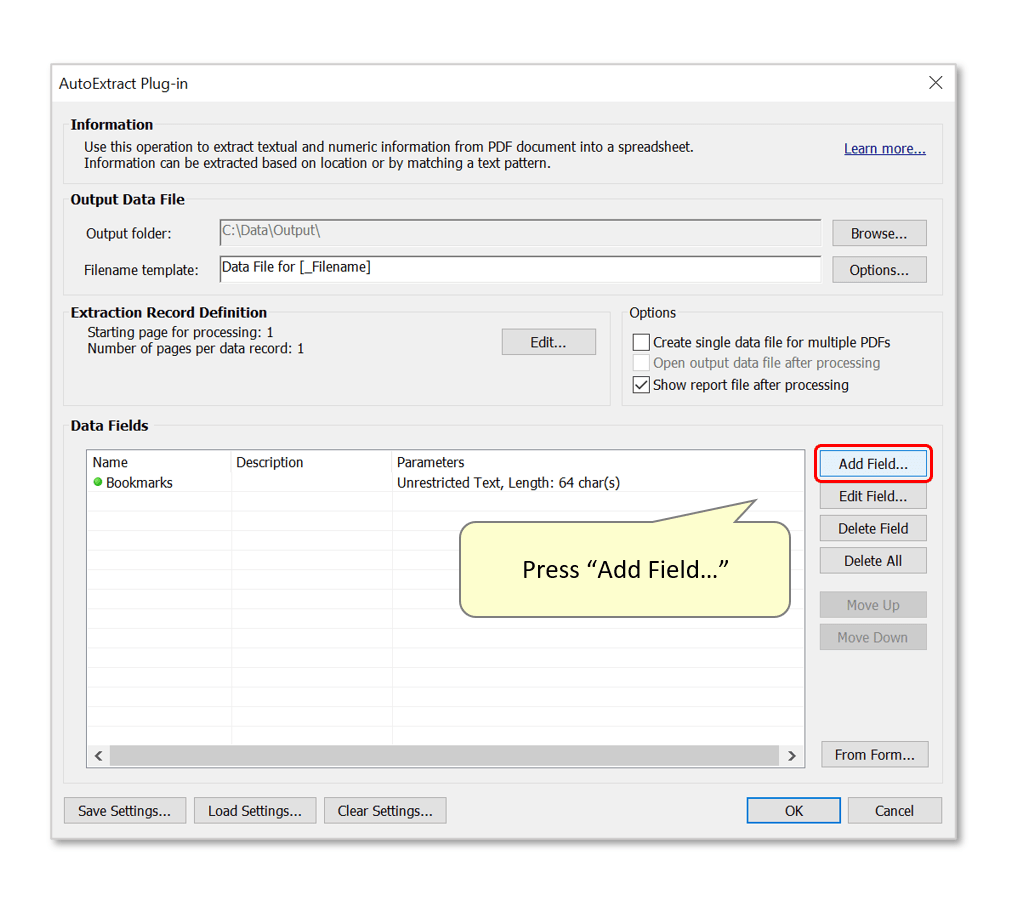
- Step 3 - Add an 'Attachments' Data Field
- Press "Add Field..." again to add another field definition.
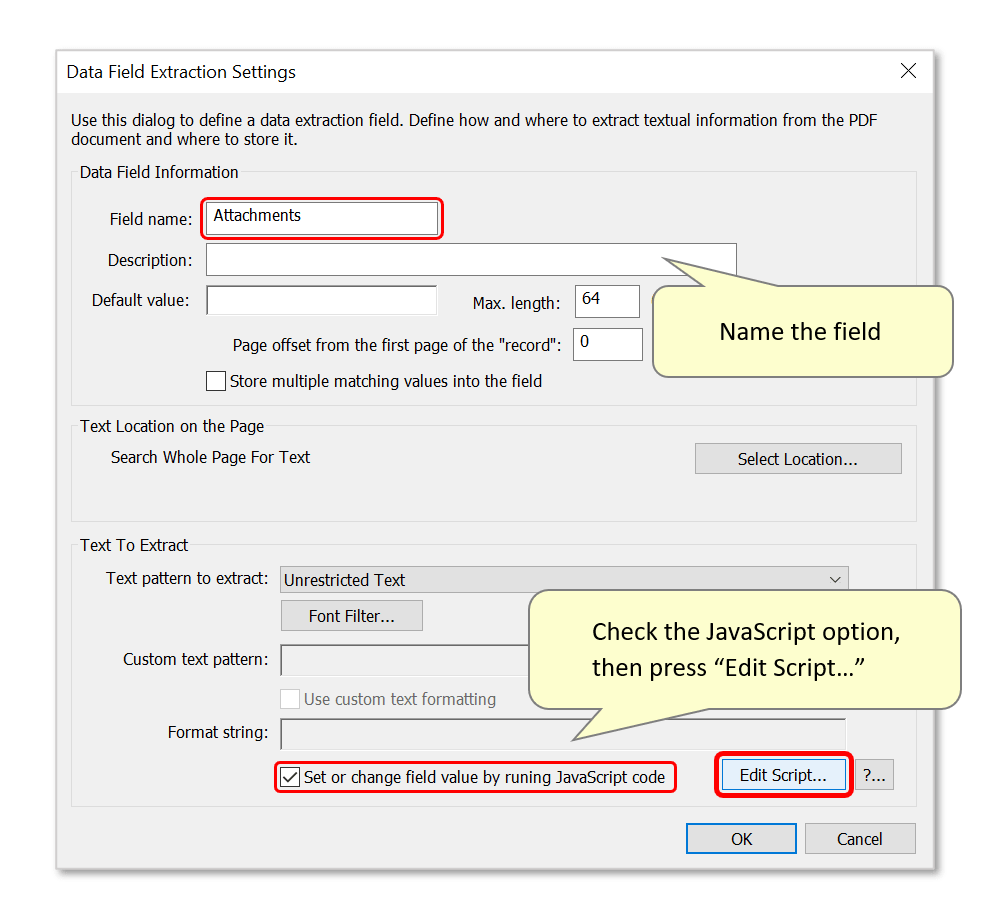
- Name the field and proceed to add a script.
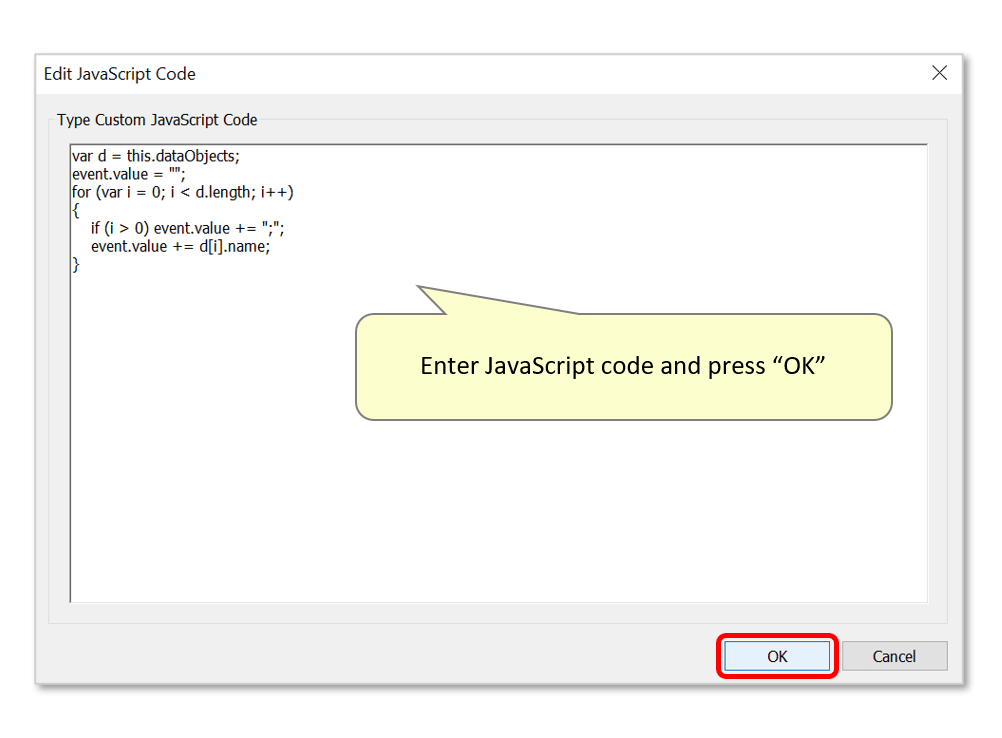
- Type JavaScript code - the code used here will get a list of all file attachments and assign it to the field value. File names will be separated by a semicolon:
-
var d = this.dataObjects;
event.value = "";
for (var i = 0; i < d.length; i++)
{
if (i > 0) event.value += ";";
event.value += d[i].name;
}
- Press "OK" to proceed.
- Step 4 - Confirm Extraction Settings
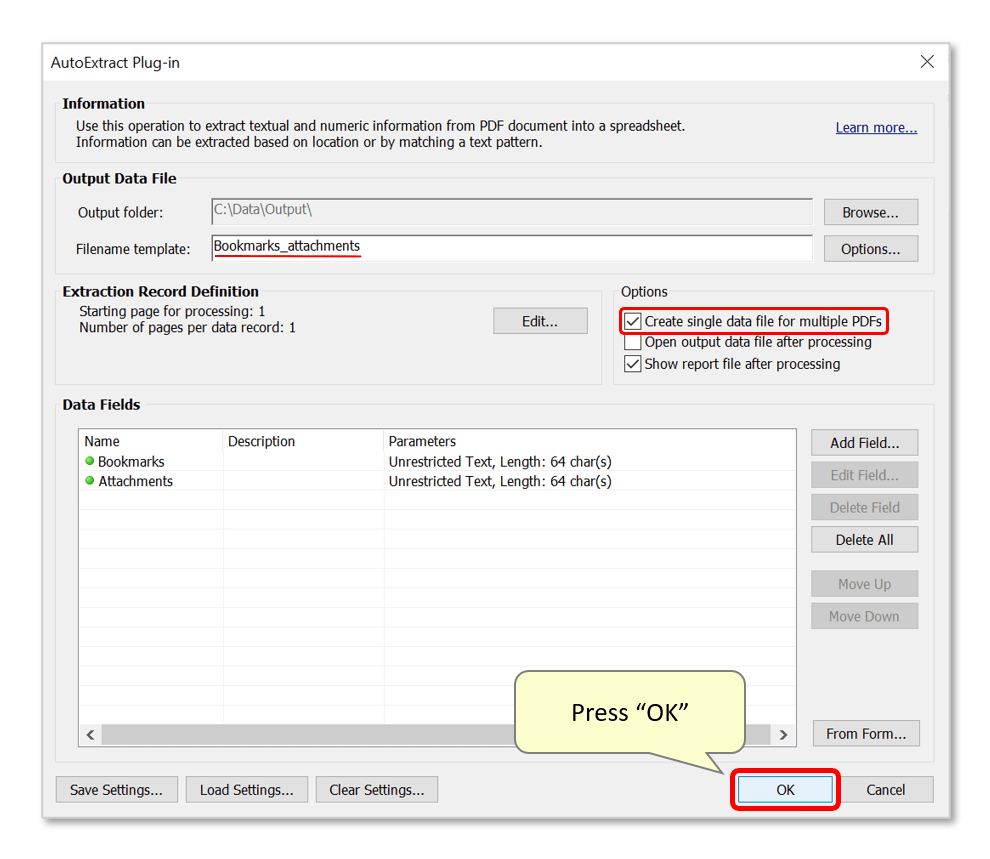
- Enter an output filename template - the output spreadsheet in this example will be titled "Bookmarks_attachments.csv". Optional: check "Create single data file..." to store extracted data from all input PDFs in one spreadsheet file.
- Press "OK" to proceed.
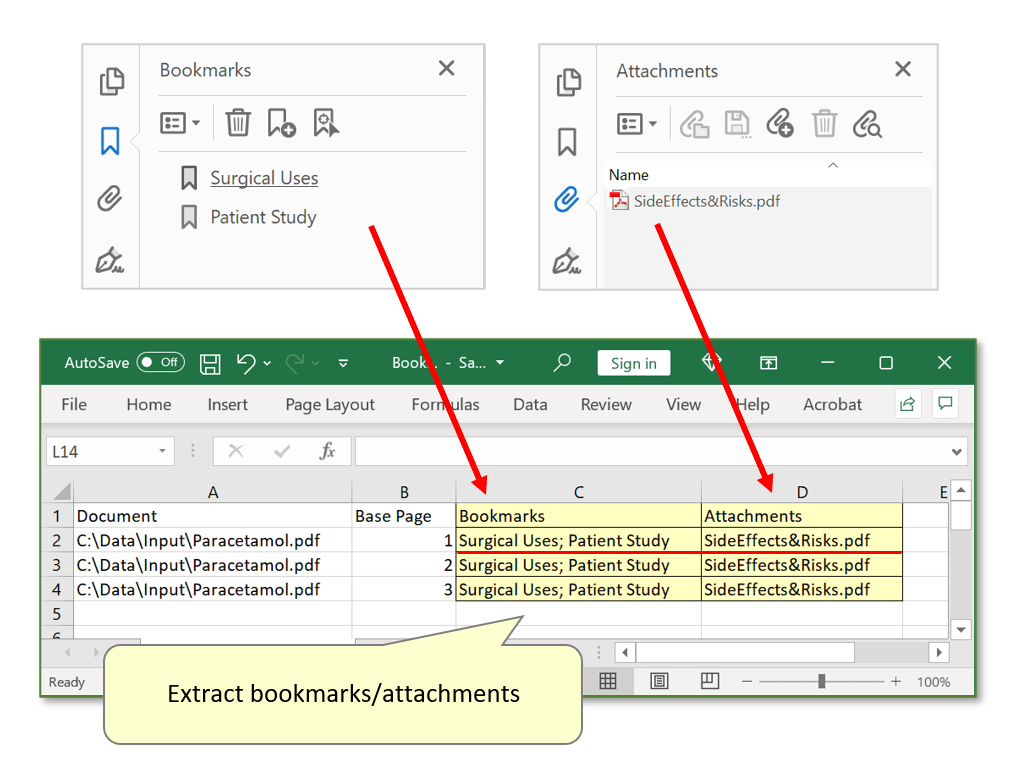
- Step 5 - Extract Bookmarks/Attachments
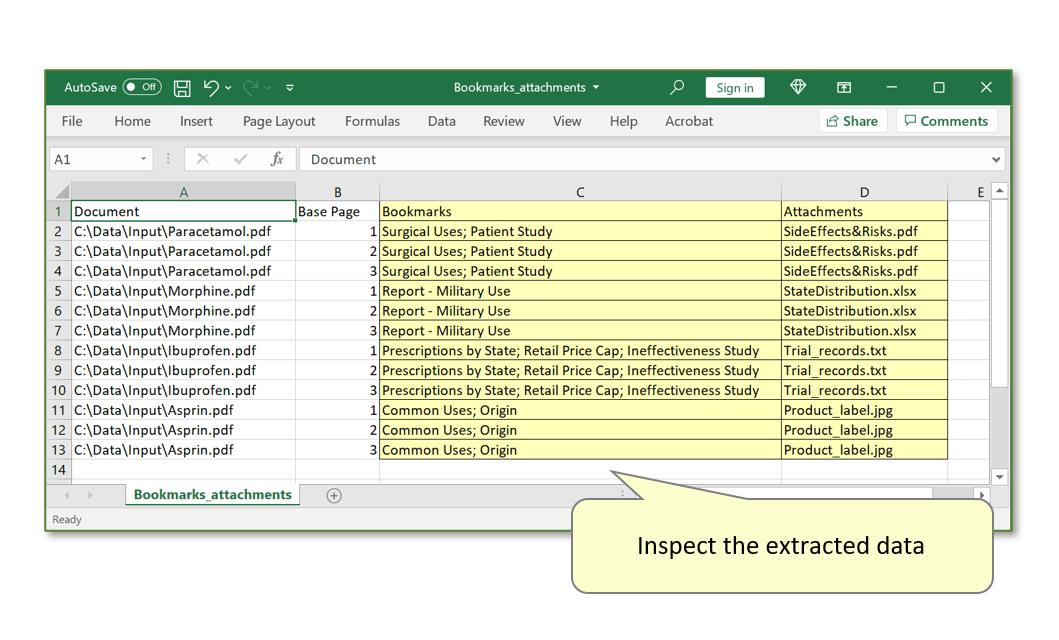
- Proceed through the next dialogs by selecting the desired input PDF documents. Run the procedure, then open the ouput spreadsheet to inspect the extracted data. Every row is a record for each input PDF - the extracted bookmarks/attachments will be presented under corresponding data field headers:
- Click here for a list of all step-by-step tutorials available.