
Extract Data from PDF Documents into Spreadsheets
AutoExtract™ plug-in Adobe® Acrobat®
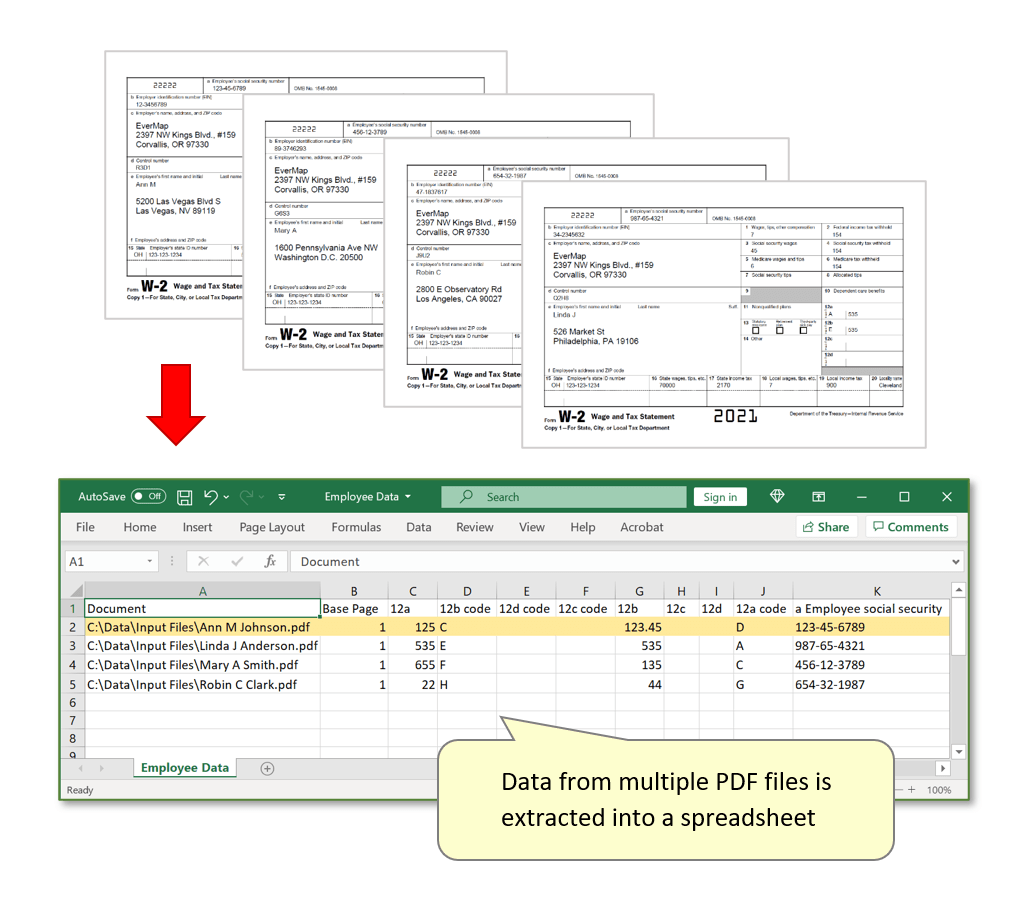
- The AutoExtract™ is a plug-in for Adobe® Acrobat® for extracting data from PDF documents into a spreadsheet file format. Use this software to collect data from business forms and documents into a structured table-like output. Data is extracted based on user-defined rules from specific page locations or based on text pattern search.
Functionality Overview
- Use Cases
- Here are few examples on how the software can be used:
-
- Extract data from non-interactive tax and business documents into spreadsheet format.
- Extract invoice numbers, total amounts, dates due, bill-to info from PDF invoices into spreadsheets.
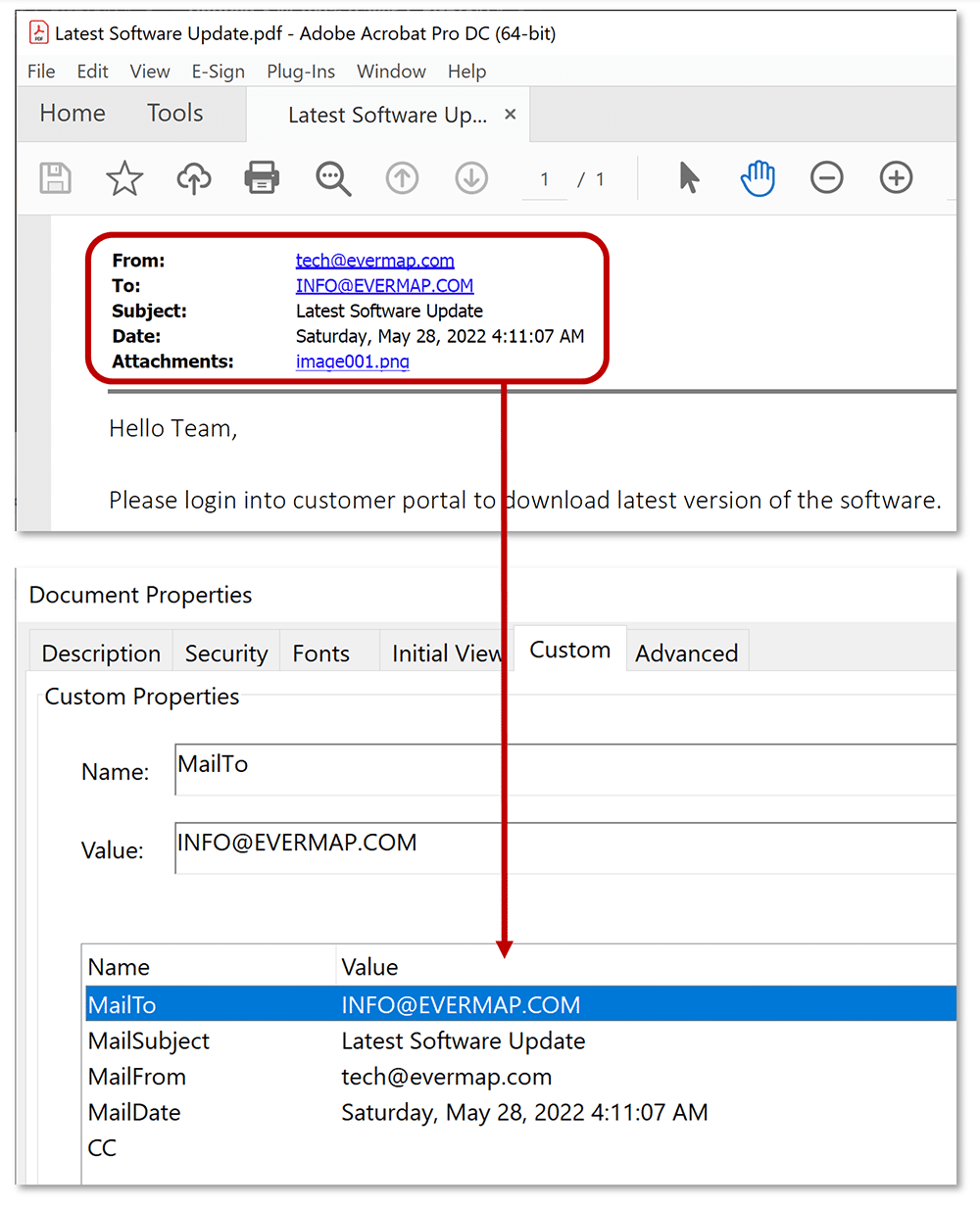
- Extract email headers information (stored as plain PDF files) such as To, From, Date, Subject, CC, BCC.
- Extract data from scanned paper documents (after Text Recognition is applied).
- Update document metadata based on data contained in PDF documents.
- Extract document metadata, bookmarks, file attachments.
- Input PDF Documents
- The software extracts text and data from searchable PDF documents. It can be used to process both fixed and variable-layout forms and documents. Most tax and business forms are generally fixed-layout forms (for example, W-2 or 1099-INT forms) meaning that each data field (i.e. First Name, Last Name etc) occurs at fixed page locations and does not change from file to file. Variable-layout forms are more difficult to handle because each data field can occur at various locations and/or may have different size, formatting and layout.
- PDF Files and Data Records
-
There are multiple scenarios how data can be extracted from PDF files:
- Each PDF file contains data for one data record. For example, each file represents a separate copy of the tax form.
- Each PDF file contains data for multiple “sub-documents”. Each “sub-document” occupies the same number of pages (for example: 1 page per document). Data from each “sub-document” needs to be extracted into a separate data record. For example, each file contains multiple tax forms (of identical type).
- Each PDF file contains multiple “sub-documents” of variable page length. For example, an input PDF file contains multiple invoices and each invoice may have different number of pages.
- Multiple data records can be present on each page in the input PDF file(s). For example, an input PDF file is actually a phone bill, and it is necessary to extract records about every call as a separate data record.
- IMPORTANT: The software is not designed to extract data from interactive fillable PDF forms. This functionality is already provided by Adobe Acrobat and is readily available via “Prepare Form” tool. The AutoExtract is designed to work with regular non-interactive PDF files.
- Output Data Files
- Data extracted from PDF files can be stored into single or multiple table-like data files using various popular file format. The most widely used is CSV (comma-separated values). It is a common data exchange format that can be directly opened or imported in most spreadsheet and database applications. The output spreadsheet is collection of columns and rows. Each column has a name that corresponds to a specific data field (for example, First Name, Last Name, Address etc). Each data row contains a collection of data fields for a single instance of the input document or "form" (for example, all fields from a single W-2 form or an invoice).
- Data Formats
-
- CSV (comma-separated values) file (*.csv)
- XML (XML Spreadsheet 2003 format) (*.xml)
- TEXT (tab-delimited values) (*.txt)
- JSON (JavaScript Object Notation) (*.json)
- Data Fields
- Data is extracted from PDF documents based on user-defined data fields that specify where the specific information is located within the document and how to process and save it. Each data field extracts data into a single named column in the output spreadsheet.
-
Data fields can define extraction areas by using the following methods:
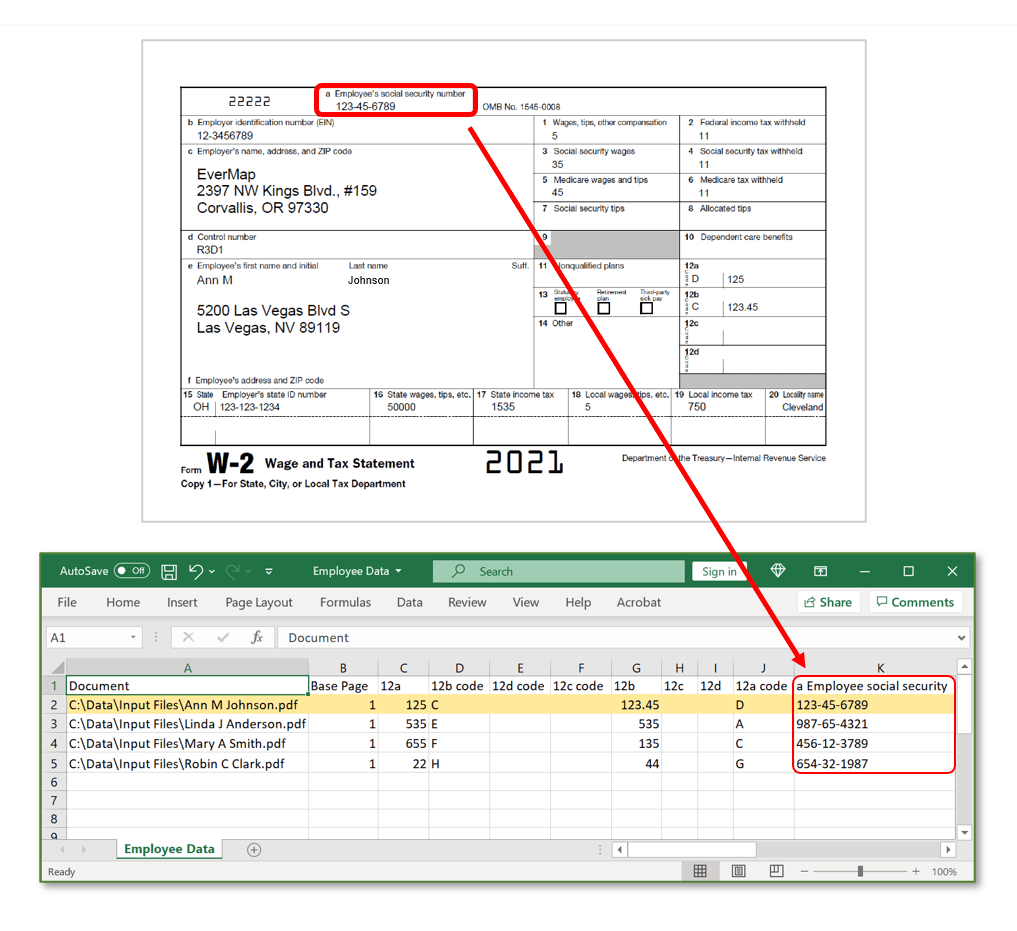
- By specifying a fixed page location. For example, a text from a 1 x 2 cm area in the upper right corner of the page.
- By searching for a specific text or pattern. For example, a 10-digit account number.
- By specifying an area relatively to the text search result. For example, 1 cm below a specific word or pattern.
- By using custom Acrobat JavaScript code to extract document's metadata or any other custom information from PDF files.
- Here is an example of a data field that extracts text from a fixed area on the page:
-
- Extracting Document Metadata
- AutoExtract can optionally output standard (Title, Author, Subject, Keywords, Creation Date, etc.) or custom metadata fields.
- Processing metadata such as "Extraction Date", "Page Number", "Document Path" is automatically included into the output data file.
- Working with Scanned Paper Documents
- Text recognition needs to be applied to scanned paper documents prior to using them with AutoExtract. This is typically done automatically by scanning software during the document acquisition. It can be also applied afterwards by using "Text Recognition" tool that comes with Adobe Acrobat. This process will make PDF documents usable for the text extraction. If you are scanning paper documents using Adobe Acrobat, then text recognition is applied by default at the time the PDF document is generated.
- Saving Data Fields into Document Metadata
- Optionally, extracted data fields can be saved right into corresponding PDF file as document metadata. This method can be utilized if single data record is extracted from each input PDF file. The following example shows how email header information is saved into custom PDF metadata fields. Metadata can be accessed via "File > Properties" menu in Adobe Acrobat, "Custom" tab.
-
- Running from a Command-Line BAT File
- Execute data extraction jobs from outside of Adobe Acrobat via a command-line BAT file. Use this method to automate data extraction by starting the processing from an another application or Windows Task Scheduler.
- Tutorials
-
- Extracting Text from PDF Files into a Spreadsheet (Fixed Document Layout)
- Extracting Text from Documents of Variable Page Length
- Defining Fields for Data Extraction
- Extract Document Metadata
- Custom Text Formatting
- Extract Bookmarks and Attachments
- Using Scripting to Redact Extracted Text
- Running AutoExtract Jobs from a Command-Line BAT File
- Contents
- Adobe Acrobat Integration
- The plug-in adds "Plug-ins > Extract Data Records from Document Text..." menu and a corresponding toolbar button to the Adobe Acrobat user interface. There is no separate application to launch - all functionality is fully integrated with familiar Acrobat interface.
- Trial Version
- Download and evaluate a 30-days fully featured trial version of the plug-in. Trial version is limited to extracting 100 records per input PDF file.
- System Requirements:
-
 Microsoft® Windows 11/10/Windows 8/Windows Server 2012/2016/2019/2022.
Microsoft® Windows 11/10/Windows 8/Windows Server 2012/2016/2019/2022.
- Software:
-
Full version of Adobe® Acrobat® software is required - Acrobat Standard or Professional (32/64-bit versions 9, X, XI, 2015, 2017-2025, DC).
This software will not work with free Adobe Acrobat® Reader®.
Batch processing functionality requires presence of Adobe® Acrobat Professional®.
(Adobe Acrobat Product Comparison Chart).