Extracting PDF Pages That Do Not Contain Specific Keywords or Text Patterns
AutoSplit plug-in for Adobe® Acrobat®
- Introduction
- The AutoSplit plug-in is useful for extracting pages from a large PDF document that contain specific search words or text patterns - but it can also be used to extract pages that DO NOT contain specific text. These may be pages that contain certain words such as names, identification numbers, dates, or address components etc. This may be useful when a PDF file consists of multiple combined documents, but only pages containing certain data need to be extracted - leaving behind unnecessary documents. For example, if a collection of invoices have been combined into one PDF file, the user would be able to use this method to extract any invoices that do NOT contain specific keywords such as customer names, identification numbers, or item numbers etc.

- Sample Document Description
- The sample PDF document used in this tutorial contains multiple combined business documents. It features a random mixture of sample invoices, purchase orders, and account statements. We will use the AutoSplit plug-in to search for specific items of text within these documents using a search expression, to extract any remaining pages that do not contain this text. The source file contains a few blank pages containing "Page 1 of X to be extracted" text, which will be the only pages extracted as they do not feature the keywords included in the search expression ("invoice/purchase order/account statement").
- We will use the “Manually Defined Page Ranges” method to specify the desired text pattern. The pages to be extracted can be located anywhere in the input document and not necessarily in continuous order.

- Batch Processing Support
- Automate this operation with Guided Actions (aka Action Wizard) tool to process similar files using the same settings with only one click.
- Prerequisites
- You need a copy of Adobe Acrobat Standard or Professional along with the AutoSplit™ Pro plug-in installed on your computer in order to use this tutorial. Both are available as trial versions.
- Step 1 - Open the “Split Document Settings” Menu
- With the file to be processed open in Acrobat®, select “Plug-ins >
Split Documents > Split Document…” from the main Acrobat® menu to open
the “Split Document Settings” dialog.
[⚡ How to locate Plugins menu in Adobe® Acrobat® ⚡] - Step 2 - Select the Splitting Method
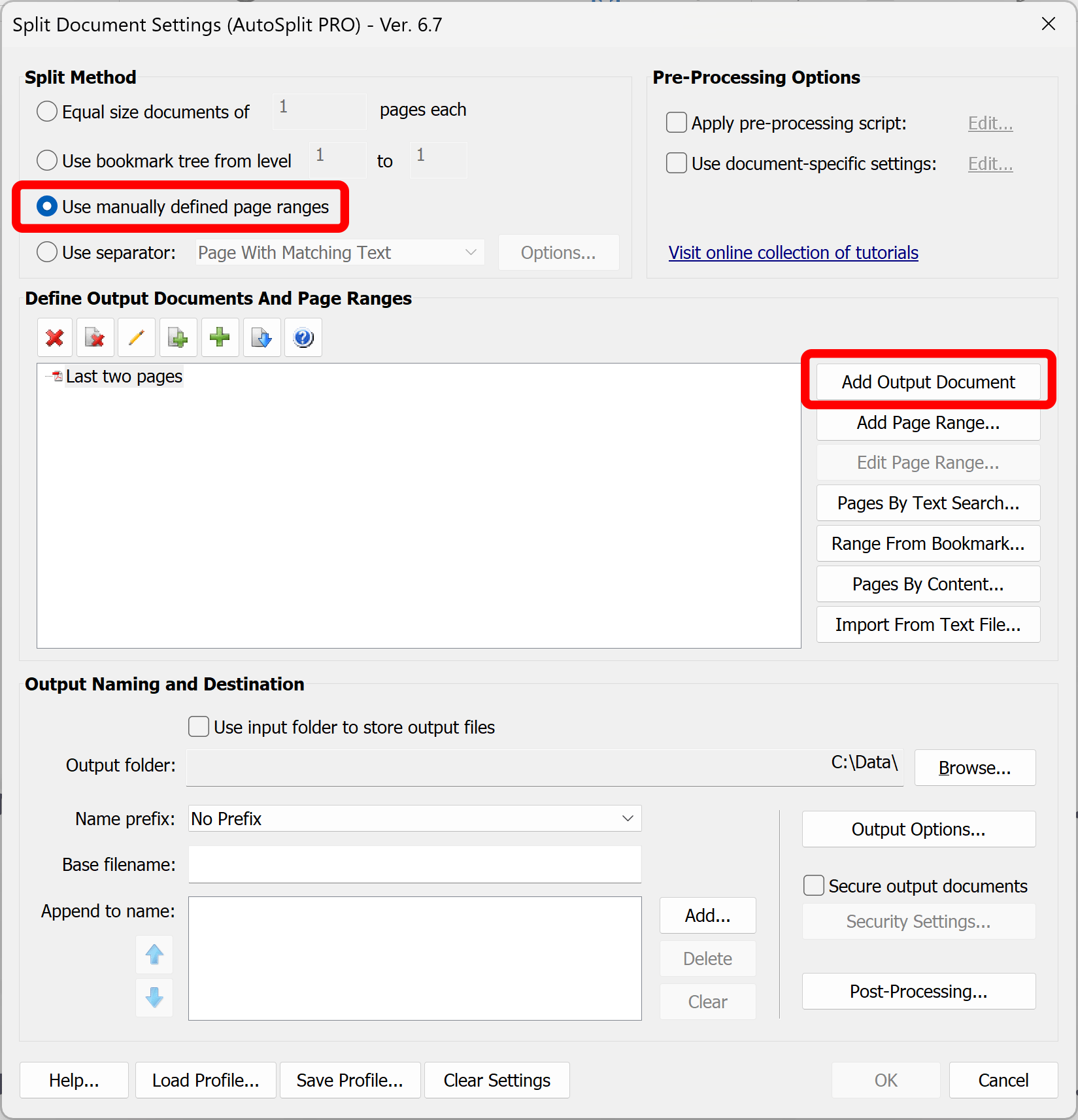
- Check the “Use manually defined page ranges” box to select a splitting method.
- Now press the "Add Output Document" button to define a new output document.
- Step 3 - Enter a Text Pattern
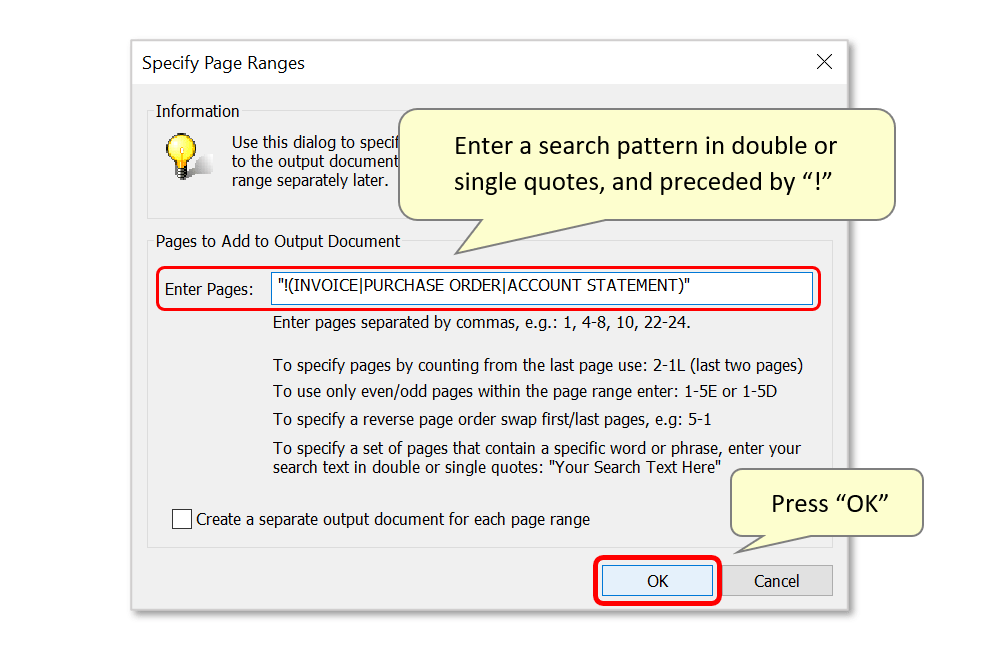
- The "Specify Page Ranges" dialog will appear on the screen. Enter the search keywords here using the format shown below:
- "!(INVOICE|PURCHASE ORDER|ACCOUNT STATEMENT)"
- Search Expression Breakdown:
- If searching for multiple keywords, separate them with vertical bars and enter all text within double/single quotes and brackets. Use “!” as the first symbol in the search pattern to negate the search results. This search pattern will instruct the plug-in to search for the presence of the keywords "invoice", "purchase order" and "account statement". As it is preceded with “!”, only the pages that do NOT contain any of these keywords will be extracted into an output file.
- Click "OK" once done.
- Step 4 - Open the Extract Pages by Text Search Dialog
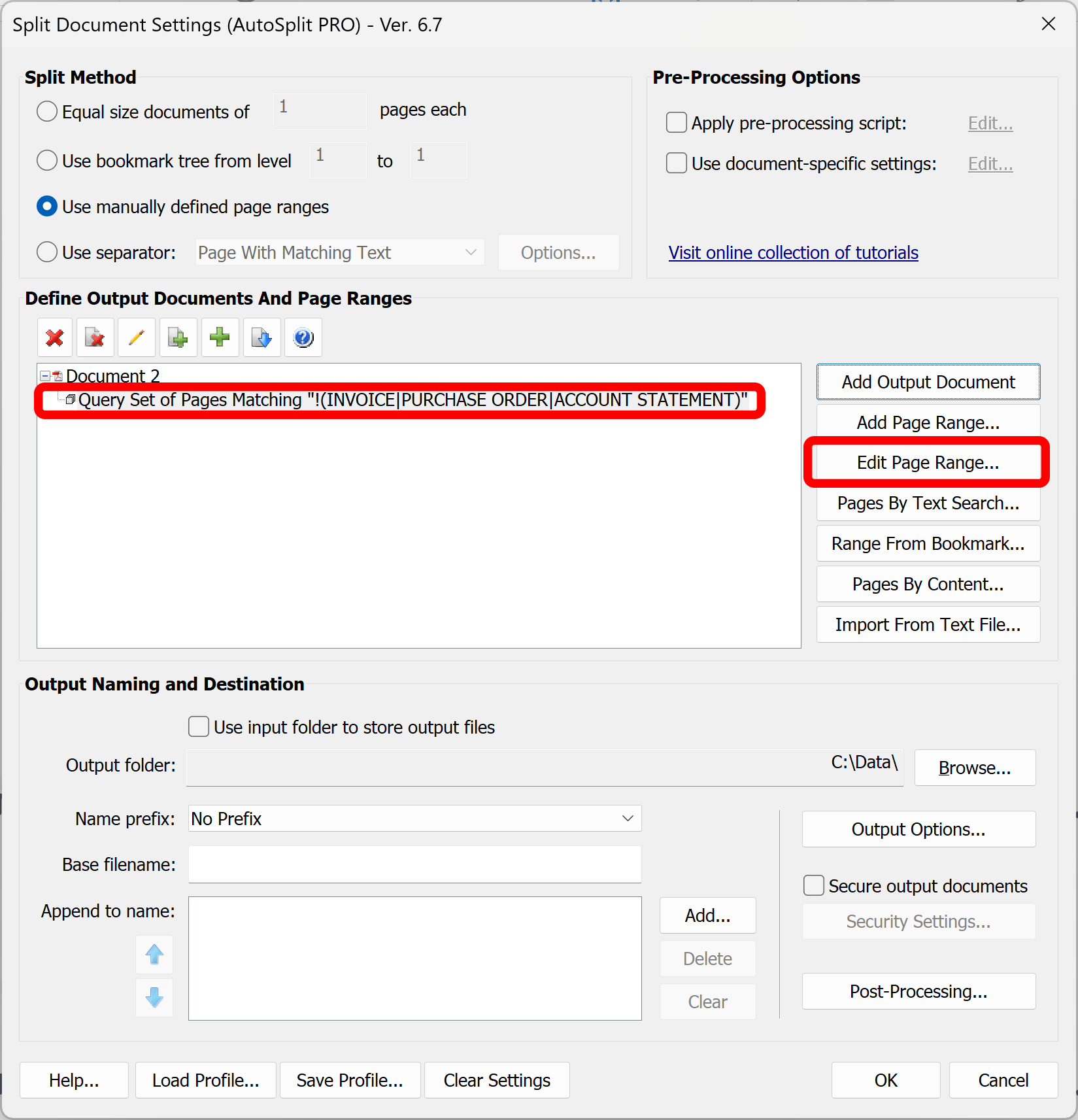
- The new document entry will be created in the output document list. By default, the output file name is set to "Document 1".
- Double-click on the new entry or select it and press the "Edit Page Range..." button to open the 'Extract Pages by Text Search' dialog.
- Step 5 - Specify Text Searching Options
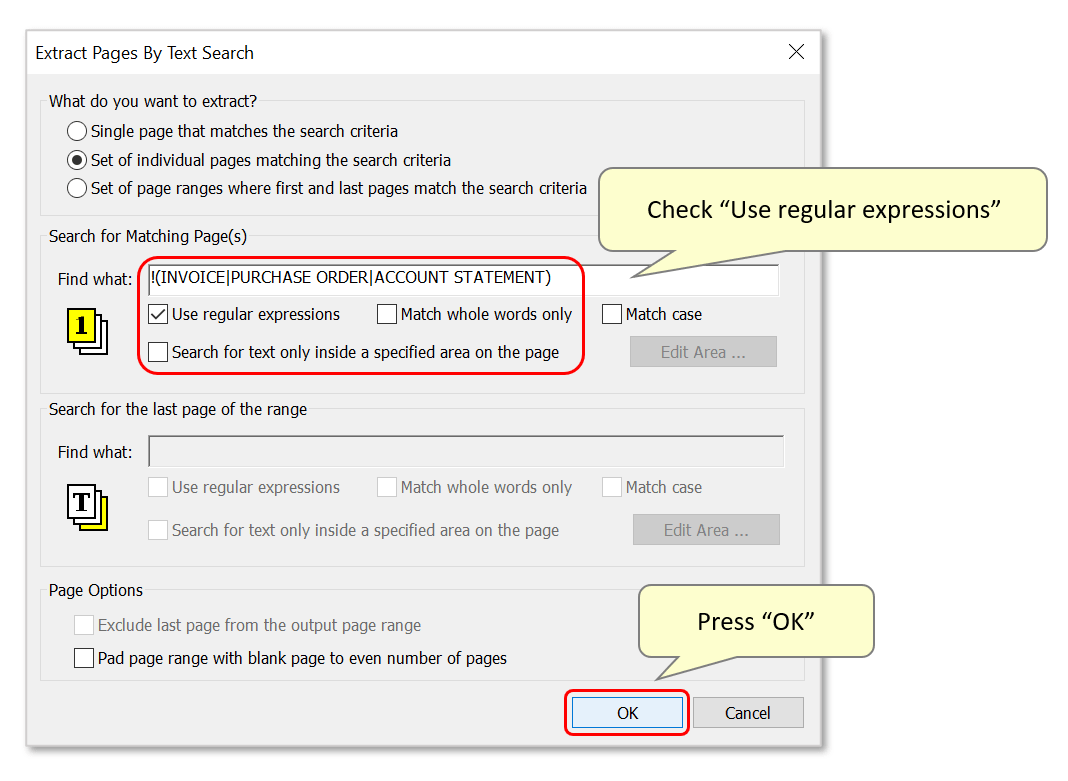
- The previously entered search expression will be shown here and can be edited if necessary.
- IMPORTANT: Check the "Use regular expressions" option to enable text pattern search, then press "OK" to close the dialog.
- Step 6 - Edit the Output Filename
- Double-click on the default 'Document 1' filename if you want to enter a custom name for the output document.
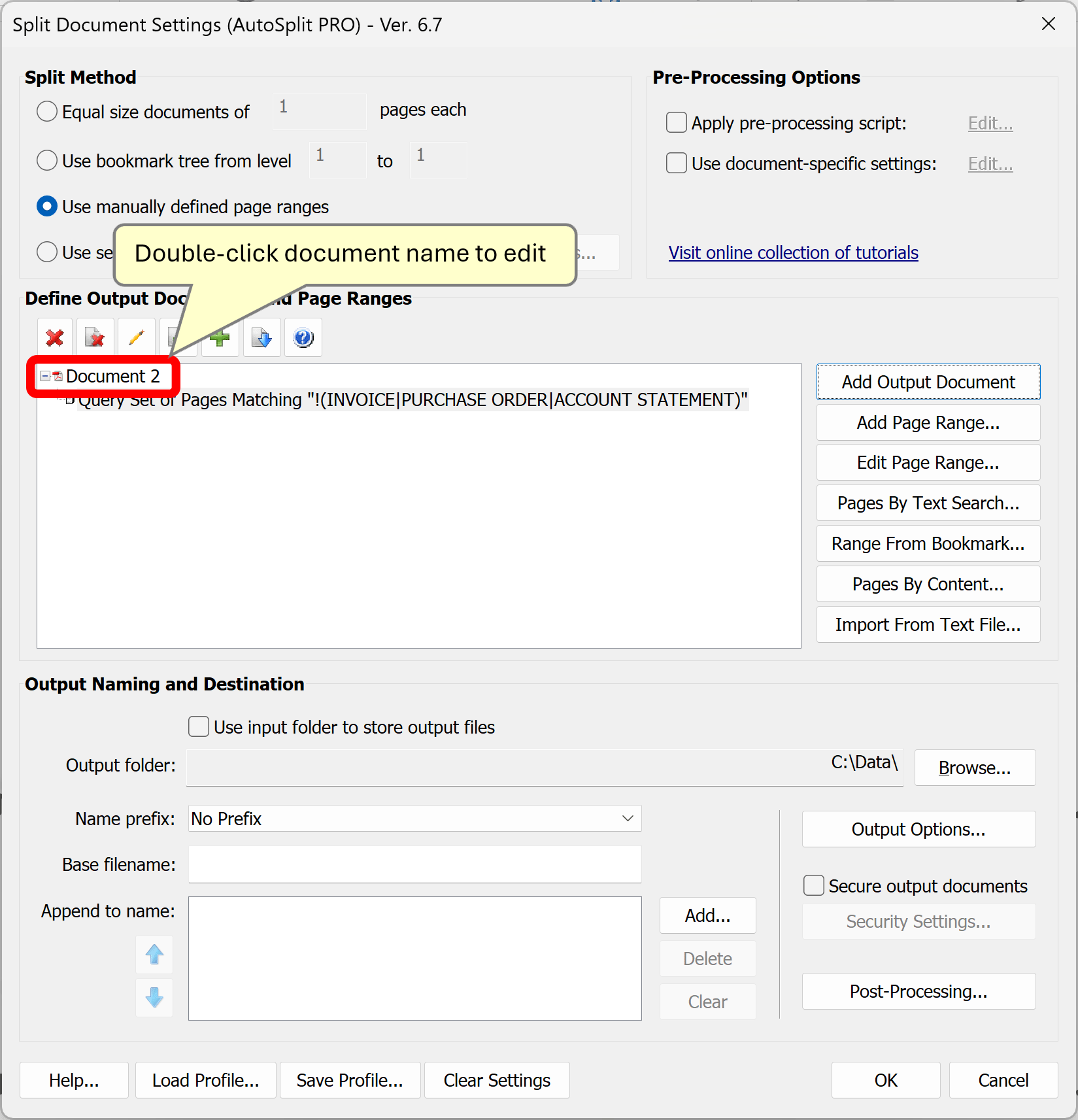
- Select the 'Use custom file name' option and specify a new filename in the entry box. Optionally, enter desired metadata properties for the output document such as "Title", "Subject", "Author" or "Keywords" etc. Click "OK" once done.
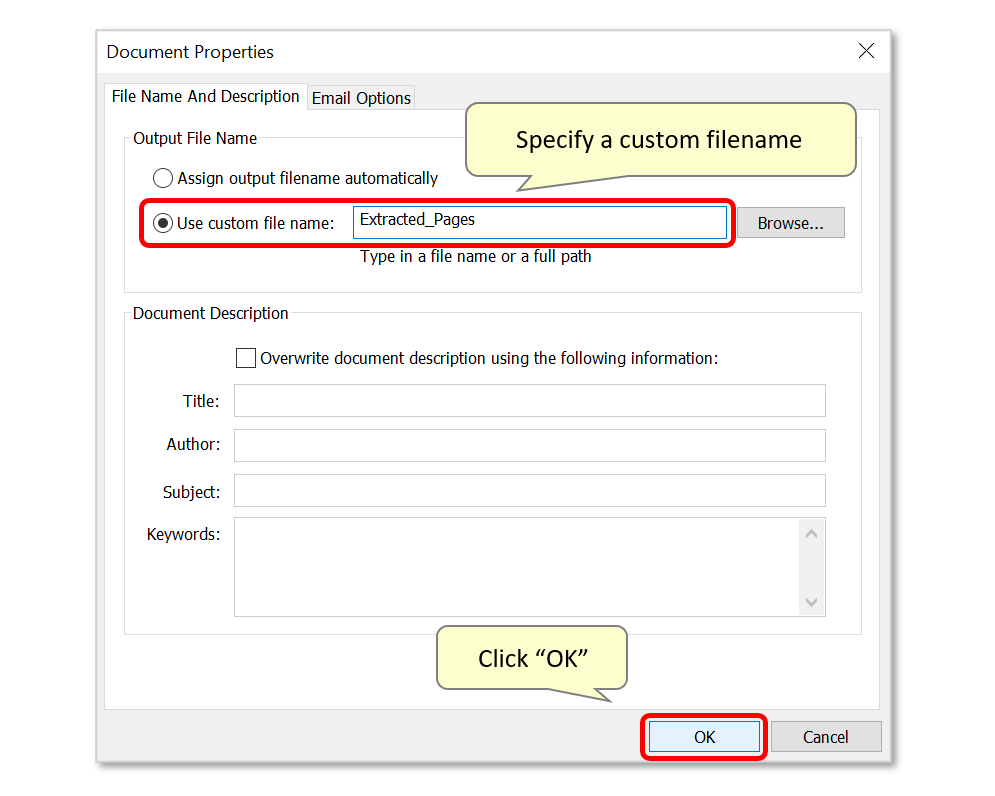
- Step 7 - Specify an Output Folder
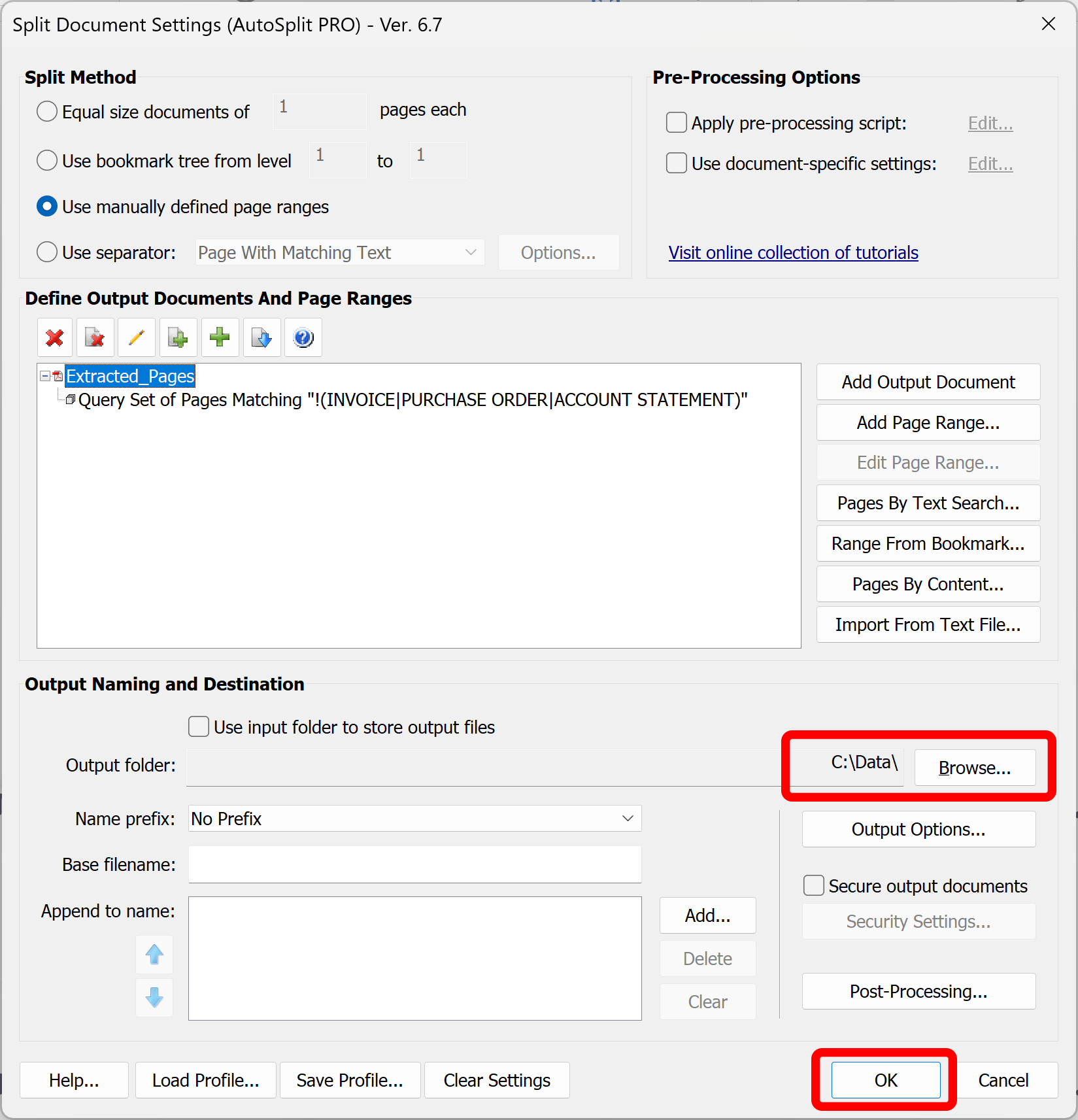
- The new filename will now be displayed. Specify an output folder location for the extracted pages via the "Browse..." button.
- Press "OK” to proceed with the extraction.
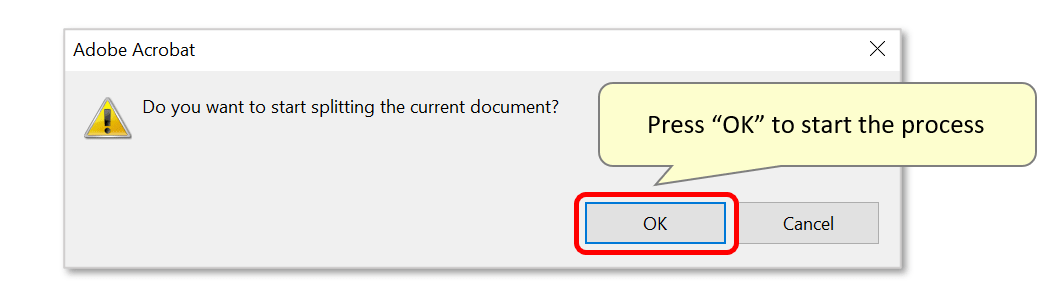
- Press “OK” in the dialog box to start the process.
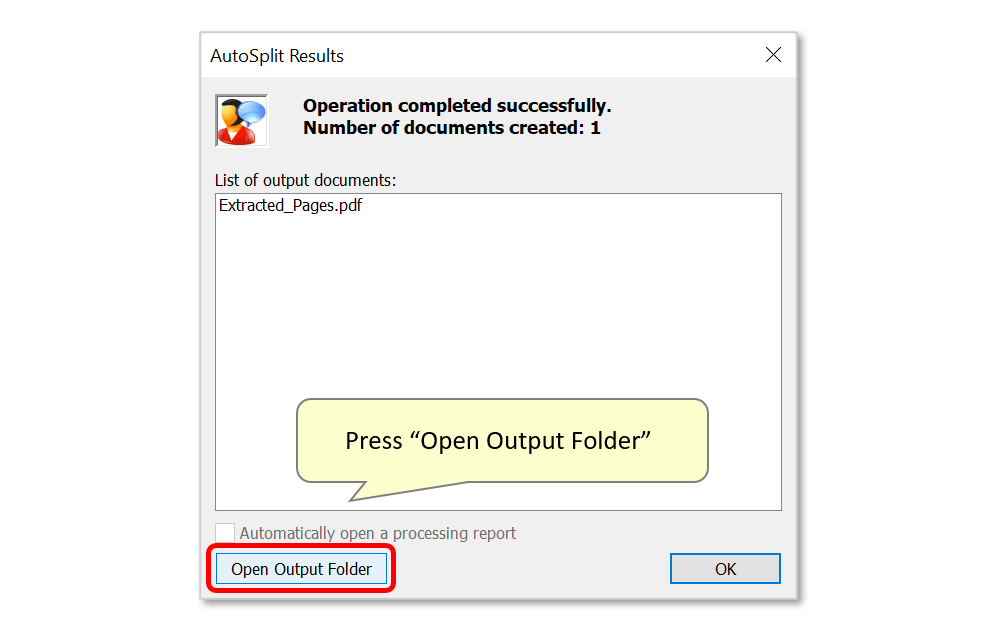
- Step 8 - Inspect the AutoSplit Results Dialog
- The “AutoSplit Results” dialog appears on the screen once processing is complete, listing files that have been created.
- Press “Open Output Folder” to inspect the results.
- Open the created file.
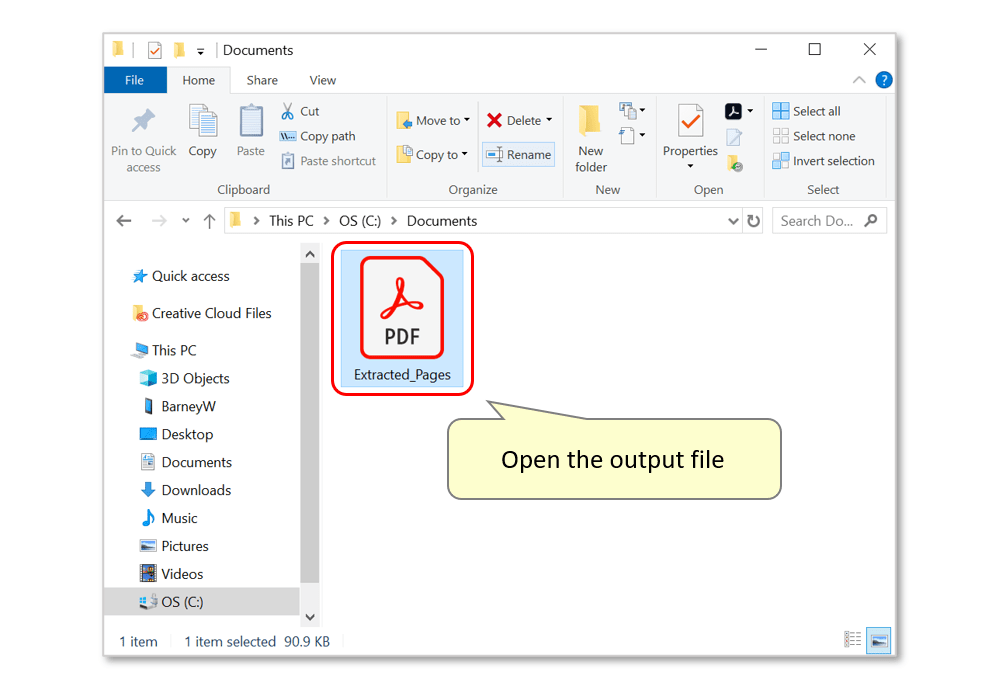
- Check the results - in this example, all pages from the input document that did not contain the specified keywords have been extracted and saved in this separate file.

- You can find more AutoSplit tutorials here.