Split, Combine & Rename
PDF Documents
Split & Combine Invoices, Statements, Reports,
Forms, Letters and Office Documents
Professional Tools for Adobe Acrobat
Split, Extract, Combine, Auto-Rename PDF Documents
AutoSplit™ plug-in for Adobe® Acrobat®
What is AutoSplit?
The AutoSplit™ is a plug-in (add-on) for Adobe® Acrobat®
software (Windows OS). It seamlessly intergrates into Acrobat's user interface and
provides advanced PDF processing for:
- Splitting PDF files into multiple by bookmarks,
page count, page ranges, specific or changing text,
blank pages, page orientation or size.
- Combining multiple PDF, Office, and image files using
a variety of automated methods.
- Deleting Duplicate pages based on document's text or
page appearance.
- Extracting and Deleting Pages
based on text content or patterns, duplicates, blank pages,
bookmarks, annotations.
- Automatically Renaming PDF Files
using document's text, metadata, page labels, Bates stamps, and more.
- Watch a Folder and apply automated processing:
auto-rename PDf files, convert documents into PDF,
optimize, watermark, etc.
See System Requirements, Security Statement and Product Information for more
details about the software or read User Testimonials.
Proven & Reliable
AutoSplit has been continuously developed since 2004 and is trusted
by thousands of companies around the world. Built in response to real customer needs,
it offers robust and advanced document processing capabilities, making it a mature
and reliable solution for businesses. Our software is backed by a
responsive and highly experienced technical support team.
Not Sure Where to Start? Ask Us for Help!
A wide selection of detailed,
step-by-step tutorials is available online . If you don’t find one that fits your specific task,
feel free to email us at tech@evermap.com — we’ll be happy to help.
Splitting PDF files means dividing a single PDF document
into two or more separate files. This is useful for extracting
specific pages or document sections
without needing the entire original file.
Splitting Methods and Features
- Split and extract pages by bookmarks
- Split by page count
- Split by page ranges
- Split at pages that contain specific text or pattern (AutoSplit Pro)
- Split at pages that contain text from a list of keywords (AutoSplit Pro)
- Split at pages where text changes (AutoSplit Pro)
- Split at pages where orientation change (AutoSplit Pro)
- Separate pages of different size and orientation into different files
- Extract pages that contain specific keywords or text patterns (AutoSplit Pro)
- Split at blank pages (AutoSplit Pro)
- Divide pages into multiple pages of smaller size
- Automatically name output files using document's text and metadata
- Password-protect output files
- Post-processing with Acrobat JavaScript
- Guided Actions support and command-line execution (AutoSplit Pro)
Read more about
PDF splitting functionality available in AutoSplit or consult
step-by-step tutorials.
Merging files means combining multiple separate documents into a single,
unified file. Use AutoSplit to combine any PDF, MS Word, Excel, PowerPoint, HTML, Text or Image
files into one or more PDF files. Non-PDF files will be converted into PDF file format and
inserted into output PDF document.
This process helps organize related content together for easier access, sharing,
or printing.
Merge Methods and Features
- Merge multiple files (PDF, image, MS Word documents, and etc.)
into a single PDF document
- Merge files from multiple folders into multiple output documents
- Merge multiple files with similar filenames
- Merge all files in subfolders into single PDF files
- Merge linked files into main PDF document
- Insert pages from single file into multiple documents
- Update multiple PDF documents by inserting/replacing pages
- Automatically generate table of contents and bookmarks in merged documents
- Merge all or only specific pages
- Use control files to perform custom document merging
- Guided Actions and command-line support (AutoSplit Pro)
Read more about
document merging functionality available in AutoSplit or consult step-by-step tutorials.
Auto-renaming PDF files is useful when managing large batches of documents,
such as invoices or reports, to ensure each file has a unique, descriptive name based on
content like date, client name, or document ID. It also helps streamline organization,
prevent overwriting files,
and improve searchability in automated workflows or document management systems.
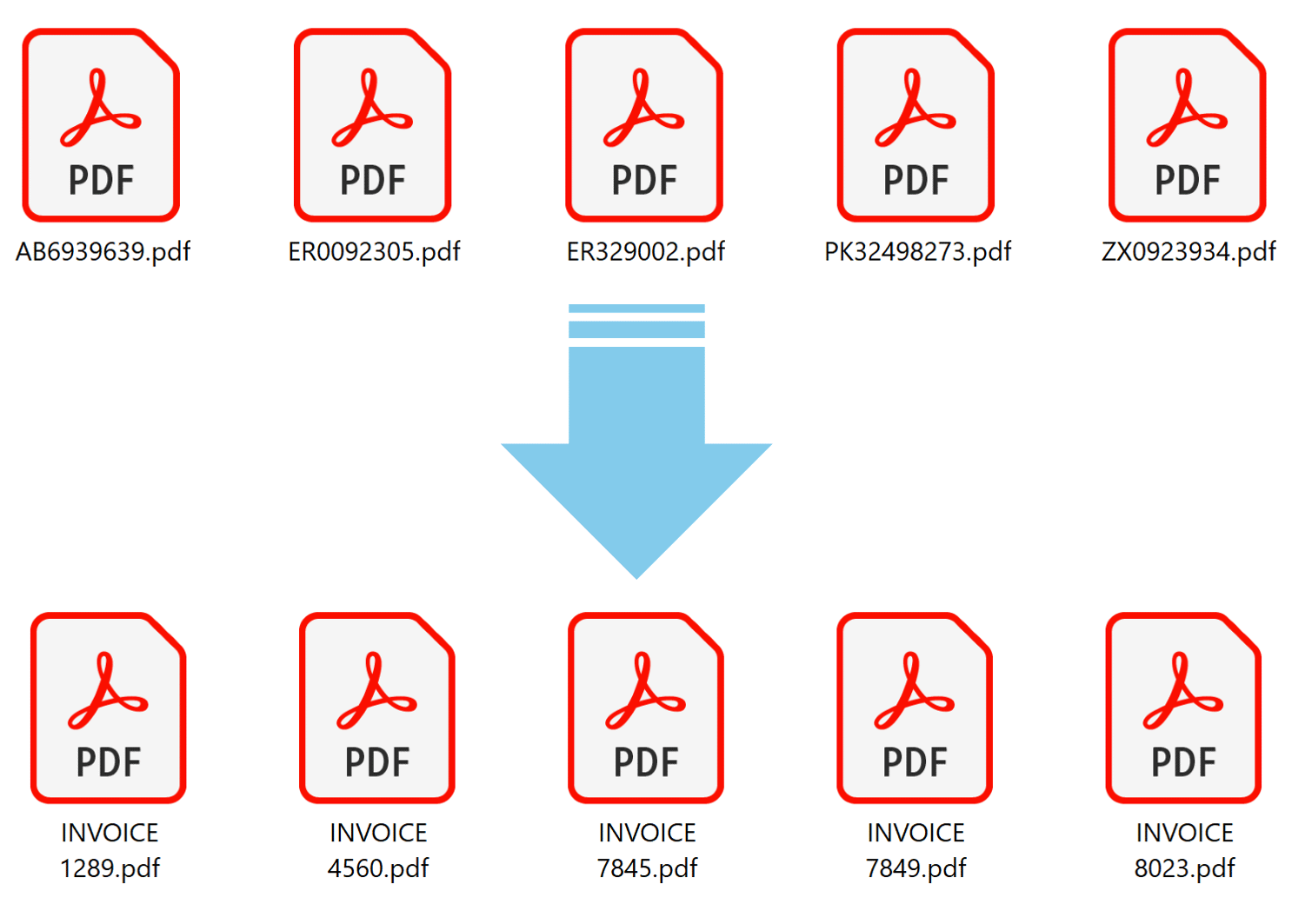
Auto-Renaming Features
- Automatically rename multiple PDF files at once
- Use any combination of text from page, metadata, custom text, Bates stamps,
auto-incrementing letters and numbers to generate file names
- Use lookup tables to rename files based on keywords, account numbers, SSNs, etc.
- Use rules to rename different document types with different settings
- Review and edit
auto-generated filenames before renaming files
- Keep track of filename changes with report files
Read more about
auto-renaming functionality available in AutoSplit or
consult step-by-step tutorials.
Monitor a
folder for incoming files and apply one or more operations:
- Convert non-PDF files into PDF file format
- Auto-Rename PDF files based on document's content or metadata
- Reduce File Size
- Enhance Scanned Pages and Recognize Text
- Perform custom processing by running Acrobat JavaScript code
- Set document's metadata, insert cover pages, add watermarks, etc.
- Digitally sign documents (not yet available, upcoming version 6.8)
You need to delete or extract pages from PDF files automatically when
processing large
volumes of documents where only specific pages are needed, such as
removing blank or duplicate
pages or extracting pages with specific text or pattern.
Automation saves time, reduces manual errors,
and
ensures consistency in workflows like archiving, auditing, or data entry.
Processing Methods
- Find and Delete Duplicate and Near-Duplicate Pages
- Find and Delete Blank Pages
- Delete Pages by Text Search
- Extract Pages by Text Search
- Delete Page Ranges
- Extract Bookmarked Pages and Page Ranges
- Assign Page Labels by Text Search
Read more about
page manipulation functionality available in AutoSplit or
consult step-by-step tutorials.
A PDF Portfolio is a special type of PDF file that can contain multiple
documents—such as PDFs, Word files, Excel sheets, images, and more—assembled into a
single container. Unlike merging files into one document, a portfolio preserves each file’s original format and allows users to view, open, and
organize them individually within the portfolio interface.
Each file in a PDF Portfolio can have associated metadata that provides additional information about the file, such as title, author, subject, keywords,
and custom fields. This is especially important when storing and processing
archived emails.
Portfolio Features
- Extracting file attachments from PDF packages and files
- Extract metadata information for PDF portfolio items
- See AutoPortfolio plug-in for Adobe Acrobat for more advanced
PDF Portfolio functionality
Automated document processing using command-line BAT files and Acrobat's Guided Actions streamlines
repetitive tasks like splitting, renaming, or converting files without
user interaction, saving time and reducing errors. This approach enables
batch execution and easy scheduling, improving efficiency and consistency
in high-volume workflows.
System Requirements ↑overview
 Microsoft® Windows 11/10/Windows 8/Windows Server 2012/2016/2019/2022.
Microsoft® Windows 11/10/Windows 8/Windows Server 2012/2016/2019/2022.
Full version of Adobe® Acrobat® software is required (32/64-bit versions 9, X, XI, 2017-2025, DC). This
software will not work with free Adobe Acrobat® Reader®. Batch processing functionality requires
presence of Adobe® Acrobat Professional®.
(Adobe Acrobat Product Comparison Chart).
Icons created by Freepik - Flaticon
AutoSplit Standard™ ↑overview
Basic package contains most of the features except batch processing and splitting by separator.
Split PDF documents into multiple
files by bookmarks, page count, page ranges and content. Extract pages that match
text patterns or contain specific elements such as forms, images and links. Apply
security settings and watermarks to the output. Merge documents by appending or
interleaving pages from multiple PDF documents. Basic package does not include
"split by separators" functionality and batch processing (Guided Actions, aka Action Wizard,
command-line BAT file support).
This is an advanced version of the software. Comes with all features of AutoSplit plus
with support for Acrobat's batch processing framework (Guided Actions, aka Action Wizard,command-line BAT file support)
and "split by separator" functionality.
Split by separator mode supports PDF document splitting at blank pages or at pages
that match a text pattern.
Product Comparison Chart ↑overview
| Split PDF documents by page count |
✅ |
✅ |
|
Split PDF documents by bookmarks |
✅ |
✅ |
|
Split PDF documents by manual page ranges or text search into predefined number
of output documents |
✅ |
✅ |
|
Merge multiple PDF, image, Office documents into single PDF |
✅ |
✅ |
|
Merge files from multiple folders into multiple PDF documents |
✅ |
✅ |
|
Merge PDF, image, Office documents with similar filenames |
✅ |
✅ |
|
Merge PDF, image, Office documents by using control file |
✅ |
✅ |
|
Auto-Rename PDF Files |
✅ |
✅ |
|
Find and Delete Duplicate and Blank Pages |
✅ |
✅ |
|
Delete Pages by Text Search |
✅ |
✅ |
|
Create page labels by text search |
✅ |
✅ |
|
Split PDF documents at "separator" pages: page with specific text or pattern, blank
page, text/pattern change, page size change, page with rubber stamp |
❌ |
✅ |
|
Support for batch processing via
Guided Actions (Action Wizard) |
❌ |
✅ |
|
Support for batch processing
via command-line BAT files |
❌ |
✅ |
Fully featured 30-day trial version is available for
product evaluation. Trial version is designed to provide full access to software
functionality, but is not intended to be used for production work. "DEMO" watermark
is added to each output page created with a trial version. Both AutoSplit and AutoSplit
Pro plug-ins can be downloaded for evaluation.
EverMap has truly transformed our reporting process.
Splitting large PDF files and auto-renaming them based on AutoSplit software has
literally saved us 3-4 days per quarter. No more tedious saving and renaming files.
The software does it for us and in minutes. The team at Evermap was very responsive to
assisting us in complex situations. I highly recommend this cost effective solution.
Michelle R.
St. John Properties, Maryland, USA
I absolutely love this product, it's exactly what we
needed and is making a whole project possible!
Suzanne B.
University of Rochester, New York, USA
Very user friendly. Efficient. It will save me days of work for many projects!
Willem Goovaerts,
Industrial Pharmacist, Brussels, Belgium.
We have been using Evermap's PDF AutoSplit plugin to split one large PDF into
smaller ones based on specific text appearing on a page, and extracting text
from a set location on that page to use as the filename. It is ridiculously
successful and most definitely top of it's game.
I tried many products and none of them do what AutoSplit Pro does, and it
works so flawlessly it’s really amazing. Auto-Split on matching text is the best
thing since sliced bread, literally.
Randall Laco,
Sr. Programmer/Analyst,
Financial Insurance Management Corp., USA
«I was tasked with archiving over ten years’ worth of financial reports for our school districts, which involved splitting and
indexing literally hundreds of thousands of composite PDF reports for purchase orders, W-2’s, 1099’s, check registers and so forth.
Evermap’s AutoSplit Pro did the job well-enough when I first tried it, but I wasn’t quite satisfied with how it was naming the output files.
In three or four e-mail exchanges with their tech support, I explained how I thought the product should work, and unbelievably,
these improvements were included in an elegant product update within just a couple of weeks! Where in the technology world does THAT happen?!
I love this company and its products.»
Steve Ramos
IT Director, Solano County Office of Education, California
